클라우드기반 시스템 운영/구축 실무
보안관제의 이해
보안관제 개념
보안관제 개요
- 조직의 정보기술 자원 및 보안 시스템을 안전하게 운영하기 위하여 사이버 공격 정보를 탐지 및 분석하여 대응하는 일련의 업무와 사전예방 및 관제시스템 운영에 관한 업무
- 쉽게 말하면 모니터링
- 무엇으로 모니터링을 할 것인가
- 모니터링도 하고 탐지된 이벤트들을 분석하고 대응하는 것을 개념이라고 보고 있음
국가 사이버 안보 수행 체계
- 2015년부터 국가 안보실이 만들어지며 사이버 안보 비서관이라는 자리가 만들어짐
- 국가 안보실에서는 사이버와 물리를 다 포함해서 통제중에 있음
- 국가정보원은 그 산하에 있음 (국정원이 행동대장이라고 보면 됨)
- 국가정보원에서는 중앙 행정기관, 광역 지자체, 광역 교육청에 대한 대부분을 관여하고 있음
- 작년부터 범위를 넓히고 있음
- 예시 : 한국은행
민간 정보통신 분야 침해사고 대응 공조체계
- 실질적 행동대장은 KISA
- 안랩, 쉴더스와 같은 민간보안업체에서 함께하고 있음 (분석 참여)
- DDoS와 같은 경우에는 ISP(인터넷 서비스 제공자)에서 적극적으로 방어해주고 있음
- 국제조직에 가입에 실시간으로 정보를 주고 받고 있음
- 웬만한 대기업들은 자체적으로 대응 중
국내 분야별 보안관제 센터 역할 및 기능
- 국가 사이버 안전 센터
- 경보 발령
- 주의단계일 때에는 밤에도 관제 근무자를 제외하고도 다른 인력들이 남아 대기해야 함
- 현재는 관심단계
- 인터넷 침해대응센터
- 민간 차원임
- 대응해주고 예방 지원
- 국제적으로 정보 공유에 참여 중
- 각 부문별 사이버안전센터 : 국가의 축소판
보안관제 기본원칙
- 무중단의 원칙
- 24시간 365일 중단 없이 지속적으로 보안 관제 업무 수행하는 것
- 전문성의 원칙
- 보안 관제 전문 업체로 지정되어야만 관제를 할 수 있음
- 단순히 관제뿐 아니라 cert 업무와 분석 및 대응 업무도 할 수 있어야 함
- 정보 공유의 원칙
- 국가 차원이 될수도 있고 민간 차원이 될 수도 있지만, 공격이 이루어지면 빠르게 공격의 정보에 대해 공유해 다른 곳에서는 예방할 수 있도록 알려줘야 함
보안관제 목적
- 보안사고 예방을 통한 안전한 서비스 제공
- 정보보호 및 개인정보 보호 법 제도 준수
- 업무수행 강화를 통한 조직의 IT 정보자산 보호
- 악성코드 실시간 탐지 및 대응체계 구축
보안관제 유형
- 원격 관제 : 관제서비스 업체에서 보안 관제에 필요한 관제 시스템을 구비하고 대상 기관 침입차단 시스템 등 보안 장비 중심으로 보안 이벤트를 중점적으로 상시 모니터링
- 침해사고 발생 시 긴급 출동하여 대응 조치
- 비용적으로 저렴하지만 문제가 발생했을 시 대응이 어려움
- 파견 관제 : 관제 대상 기관이 자체적으로 보안관제 시스템을 구축하고 보안관제 전문 업체로부터 전문인력을 파견 받아 침해 및 장애 발생 시 즉각적인 관제 업무 수행
- 즉각적인 대응이 가능하고 업무 연속성이 높지만 인력 관리가 필요하고 단가가 비쌈
- 자체 관제 : 보안 관제 시스템 및 전문 인력을 자체적으로 구축하고 운영
- 단점은 전문성이 떨어질 수 있고, 최신 기술과 동향 정보 확보가 어려움
- 하이브리드 관제 : 두 가지 관제를 섞어서 쓰는 것
- 클라우드 관제 : 다양한 장비가 있어 적합하게 활용하면 최적화된 보안장비를 구축할 수 있음
- 리스크가 크고 업무 이해가 어려움
보안관제 시스템의 구성 개념
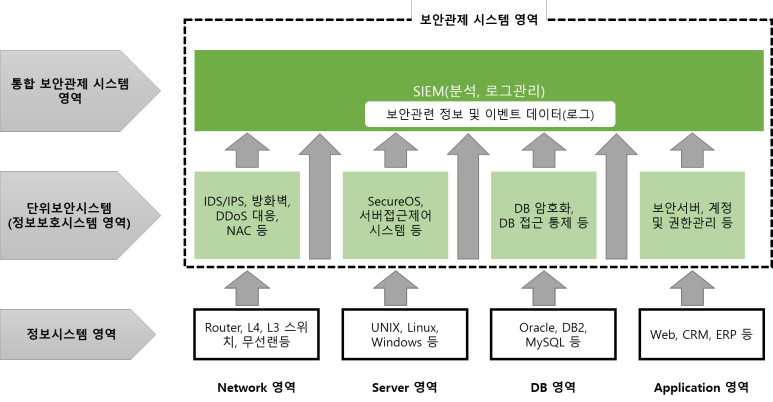
보안관제 패러다임의 세대별 변화
- 1세대 : 단위보안관제
- FW / IDS / WAF / DDoS 하나씩 따로
- 2세대 : 통합 보안 관제
- 관제 범위 확대
- ESM 기반 보안관제(상관분석 : 복합적 공격이 하나의 이벤트로 뜨게끔)
- 어느 장비에서 어떤 로그가 발생했는 지 알 수 있어서 획기적이었음
- 로그 필드에 따라 파싱을 직접 해줘야 했음
- 종합 분석 시스템이 있었으나 데이터가 방대하고 느려지는 단점이 있었음
- 3세대 : 빅데이터 보안관제
- SIEM 기반 관제
- 시나리오 관제
- 요즘은 Splunk와 Elastic 많이 쓰임
- 4세대 : 차세대 보안관제
- 머신러닝(AI)기반 이상행위 탐지
- SOAT 기반 자동화 대응
--> 개발자가 play book 생성 > SOAR에 적용시킴
--> 앞선 보안 관제 시스템 통합해서 이벤트 발생하면 사람에게 알려줌
- 위협정보 관제 연동
- 정책 user 벤더 -> 상관분석 -> 시나리오 -> Play book
관제시스템에 따른 분류
- 네트워크 공격에 대한 모니터링
- IDS, IPS, Firewall, TMS 등
- 웹 공격에 대한 모니터링
- WAF, IDS와 방화벽의 로그 비교 분석
- 서버 및 네트워크 장비에 대한 공격 모니터링
- 서버 관리 시스템, 네트워크 관리 시스템
- 사용자 컴퓨터 모니터링
- NAC, APT 시스템, 백신 등
- 통합 보안관제 시스템을 이용한 보안관제
- 다수의 시스템으로부터 수집된 정보를 종합적으로 분석
보안관제 인력
- 주간 근무자 : 일일뉴스, 보안 이벤트 보고서 작성
- 야간 근무자 : 일일 보안관제 보고서 작성 => 자동화
- 보안 관제 담담자 : 관제 조직 관리
- 전문 업체 관제 인력 : 관제 근무자들 업무와 비슷
- 보안관제 기본 스펙
- 침해사고 대응 (CERT)
- 서비스품질(SLA) : 보안관제 이벤트 발생 시 제한된 시간 이내에 처리해줘야함
--> 재계역 여부 결정하는 요소 중 하나
보안관제 업무 개요
보안관제 업무 기본
- 모든 기업에서 보안 관제 방법론을 갖고 있음
- 정보수집 : 국가 및 국제 조직에 의해 나오는 정보 혹은 장비들의 벤더사에서 나오는 정책과 같은 것들을 갖고 사전에 RULE을 정하는 것
- 모니터링 및 분석 단계 : 정보가 올라오면 수집하는 것과 각각의 이벤트를 분석하는 것
- 대응 및 조치 단계 : 정탐이라 판정 시 대응하고 처리하는 것
- 보고 단계 : 최종적으로 보고하는 것 ( 지속적으로 보안 담당자에게 상황보고 하긴 함)
보안관제 업무 절차
- 정보수집 -> 모니터링 및 분석 -> 대응/조치 -> 보고
- 예방(정보수집) : 관제/진단 업무에도 포함 (취약점 제거 > 공격/장애)
- Black IP/ URL 수집
- 탐지 : 보안 정보 분석 (ESM이나 SIEM)에 들어간 것
- 운영
- 조기점검, 가용성 점검 : 각 시스템 전부 조사하는 것은 아님
--> ESM / SIEM / EMS(MMS)에서 장애가 나는 지 모니터링 해줌
- 대응 : 이벤트 발생 시 상황 판정
- 보고 : 대응에 관해 보고
- 공유 및 개선 : 정보 공유 및 방법론 개선 절차
보안관제에서 중요하게 보는 것
- 유해트래픽 탐지 및 초동 조치
- 상관분석에 의한 모니터링 정책
- 보안관제 시스템의 안정성과 가용성 확보
*침해위협 탐지솔루션-> 침해로그(경보기준) -> 보안관제 시스템 -> 분석을 통해 정탐으로 판명 시 해당 담당자에게 전달됨 (본사 근무자 혹은 지사 근무자) -> cert 출동 후 분석 및 대응 후 다시 업무 담당자에게 보고 (업무 담당자는 국정원, KISA와 같은 유관기관에 침해대응 협조)
통합보안 관제 모니터링 처리 과정
- 본부(본사)/ 소속, 산하기관 (지사)
- 위협 관리시스템 : IDS, IPS 기능 들어가 있음
- 정부, 공공 기간, 국정원에서 많이 사용됨 국정원에서 기관에 Rule을 배포함
- 홈페이지 개인정보(WMS) : 홈페이지가 변조가 됐거나 장애 발생 시 경보를 울려줌
--> 각각 URL, Source 등록 : 자동적으로 크롤링 해주는 것 + 개인정보 노출점검 시스템
--> 홈페이지는 메인 페이지 등록하고 개인정보는 게시판 기능 갖고 있는 페이지에 등록 후 기존 소스와 비교해서 경보 / 이기종 보안장비
- 시스템에 의해 로그가 올라가면 아까 말했던 경보 기준에 의해 분석을 하게 되는 것
- 데이터 수집 및 관리 -> 사고 분석 / 위험도 분석 / 공격성향 분석
- Top/Trend 분석-> 정보 공유 포털과 내부 포털에서 정보 처리
보안관제 구성 요소
- 네트워크 영역 : NAC(Netsork Access Control)
- PC와 서버 등로
- 서버 영역
- 통합 및 분석 : ESM/SIEM
보안관제 구성 요소(보안관제 시스템 측면)
- 전송 : 에이전트
- 각종 보안 장비 및 서버, 네트워크에 설치되어 해당 시스템에 적합한 설정에 따라 로그 정보를 실시간 관제센터에 전송(비쌈)
- Port Forwarding(Agentless) : 보안장비/ 서버 port 약속 - > 편한, 하루 트래픽 양 분석 필요
--> 트래픽 넘어가면 로그 수집 안됨
- 저장 : 정보 수집 서버
- 저장권장 기간 : 1년
- 분석 : 통합 관제용 시스템(LM/RM)
보안관제 업무 절차
보안관제 업무 절차 기본
- 모니터링
- 비정상 이벤트 : IDS/IPS, F/W, WAF
- 비정상 트래픽 : DDoS
- 홈페이지
=====여기까지 이벤트 발생 가능 영역
- 시스템 가용성
- 정탐 : 관련 내용 메일 발송
- 오탐 : 정책관리
- 장애 : 장애관리
- 작업 : 작업관리
- 기관/ 담당자 보고 <-> 조직관리
- 이력관리(산출물)
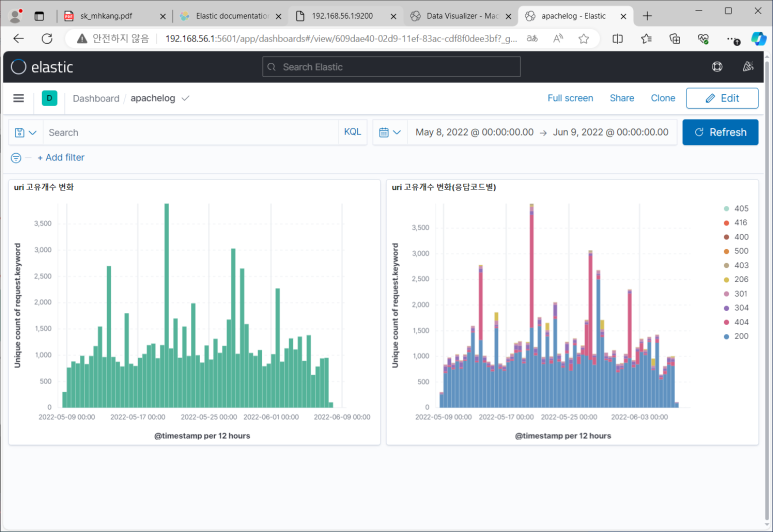
(실습) 이벤트 처리 절차도 작성
- 현업 부서
- 신고: 보안관제 팀에서 모든 것을 모니터링 할 수 없음
- 상황 대응
- 보안관제
- 신고 접수 → 로그 확인: 행위 시점 확인 가능 → 보고
- 신고 접수되거나 침해 탐지되었을 때, 무조건 네트워크 분리해달라고 현업 부서에게 요청함
- 침해 대응 팀이 있으면 요청 or 없으면 본사의 CERT 팀에 지원 요청
- 상세 분석 (침해 대응)
- 모니터링 → 정탐 이면 초기 분석 / 오탐이면 예외처리 확인 (예외처리 적용 시 정책 관리 대장 또는 이력 대장에 기록)
- 분석 결과 보고서 작성 후, 대응 방안 작성
- 침해 대응: 사고가 터졌을 때 출동해서 대응
- 해당 침해된 서버에 가서 로그 모두 받아 분석 실시 (2~3일) 후 보고
- 보안 진단
- 분석 지원
- 개선 가이드와 같이 대응 지원
보안관제시스템 운영 업무
- 업무절차 : 모니터링 -> 티켓발생/접수 (티켓처리시스템 - SPlunk, Q-Rader로 API연결) -> 정오탐 판별 -> 공격자 IP 차단 -> 담당자 보고 -> 정책 변경 -> 이력관리
- 이상징후 탐지 고도화 : 최신 공격 기법 자료 수집 및 분석
- 관제 미처리 오류 이벤트 : 교육 강화, 크로스 체크하여 이상여부 확인, 자체 모의 훈련 실시
- 시스템 장애 발생 : 빠른 조치를 위해 전파하는 것이 임무(장애를 철리하는 일을 하는 게 아님)
- 어떤 상황에 어떤 프로세스를 내렸다 올리는 지 확인 필요
- 프로세스 내렸다 올리는 긴급 처방은 가능
- 빠르게 유지 보수하는 엔지니어에게 연락 ( 항상 비상 연락망 갱신해야 함)
보안관제 업무절차
초동분석

- 관제에서 쓰이는 초동분석은 순수하게 보안장비에서 수집된 로그를 분석하거나 네트워크로 들어오는 것을 분석하는 것을 말함 (보안관제 근무자가 로그를 보며 확인하는 것)
- 침해 대응에서는 현장에서 이루어지는 것
- 로그분석 : 실제로 공격이 이루어지는 것은 IDS/IPS, WAF 단에서 확인 가능
- 방화벽에서는 맨 처음 공격이 시작된 시간을 확인 가능
- 연관성 로그 분석 : 각각의 장비에서 연관되는 로그를 분석해 보는 것
- 방화벽, 각각 보안 장비에서 1-3개월 로그 파악
--> 공격 언제부터 시동했는 지 파악
- IDS/IPS 에서 확인되는 것이 가장 이상적인 것
- WAF 에서는 탐지가 되는데 IDS/IPS에서는 탐지가 될 수도 있고 안될 수도 있음
--> 왜냐면 여기엔 정택 넣어줘야하기 때문에
--> IDS/IPS 있더라도 WAF는 갖고 있음
- 패킷분석 : 이건 보통 DDoS에서 많이 사용됨
- 로그분석, 연관성 로그분석, 패킷 상세분석이 완료되면 기관 담당자에게 확인 요청을 받고 침해 사고 맞는 지에 관해 판단하고 맞다면 침해사고 분석이 진행되고 아니라고 판단되면 이력관리를 하게 됨
- 과거 이력 조회 : 3개월치의 IP를 조회해봐서 이전에 같은 공격을 해봤는 지 확인해 보는 것(이것도 티켓에 포함해서 보내줌)
* 이벤트와 티켓을 혼용해서 사용중인데 이벤트는 각각의 보안 장비에서 발생하는 로그들을 갖고 정책에 의해 발생한 것들을 말하는 것이고, 티켓은 SIEM과 각각의 보안 장비를 연결해서 이벤트가 올라오면 관제 근무자들에게 알려주게 되고 그 이벤트들을 근무자들이 접수하면 티켓이라고 말함
정책관리(Black IP/URL)
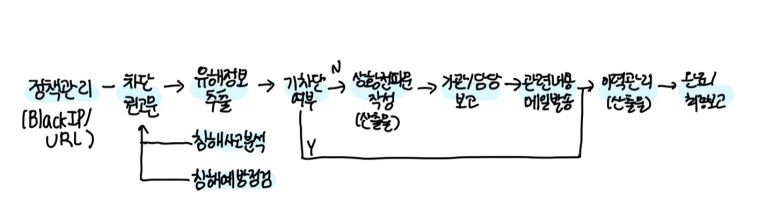
- 침해사고가 발생했을 경우나 예방 점검 시 혹은 보안 권고문을 받아 수집된 것들을 차단하는 것인데 차단 권고문은 단독으로 관제를 하다보면 작성을 할 때도 있고 안할 때도 있지만 지사가 있는 경우에는 권고문을 작성해서 유해 정보에 대해 보내주게 됨
- 그럼 IP나 URL들을 정책에 적용하게 되는데 6개월이 지나면 삭제되므로 확인해보고 차단이 안돼있으면 순서에 따라 적용하면 되고 되어있으면 이력관리만 작성하면 됨
- 공공기관을 보면 국정원이 정부부처에 전달하고 다시 근무 사이트로 전달하게 됨
*TMS : 각각의 정부부처와 근무기관에 연결이 되어있음 그래서 이 TMS 룰이 정부부처를 거쳐 지사로 배포되는데 새로운 룰이 만들어져 배포가 되면 정부부처에서 Rule을 다 뜯어본 후 새로운 IP나 URL이 있는 지 확인해서 리스트를 추출해 각각의 지사로 IP/URL 차단 요청을 하게 됨 지사에서는 업무 환경에 따라 중복 확인하지만 하다보면 IP/URL이 중복되는 경우가 생김
정책관리 (정책 넣는 것)
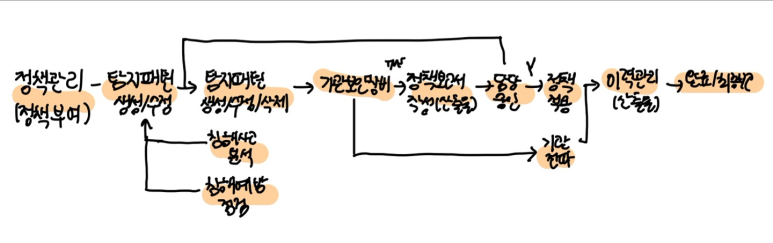
- 침해사고 분석과 점검 과정은 같음
- 분석 중 적용해야하는 내용 확인 후 적용하면 됨
- 적용하는 순서는 거의 같음
- 탐지 패턴을 만들어서 적용할 경우 가장 먼저 생각해봐야 할 것이 있음
- 서비스 영향도 : IPS나 WAF 같은 경우 차단 기능이 있음
--> 정책 생성 시 무조건 차단으로 적용하면 안됨
- 새로운 것을 생성하려고 할 때 우선 탐지모드로 넣어보고 1개월 정도 탐지 모드로 테스트 기간을 거쳐 오탐이 많다면 개선을 시키고 정탐이 많다면 그 때 차단 정책을 넣도록 함
- 긴급상황이고 중요한 것이어서 당장 차단을 해야한다면 탐지모드 없이 바로 차단을 해야함
- 적용 전 반드시 담당자의 승인 거쳐야 함
- 이력관리 필수(정책변경보고서에 생성 및 수정 상황 작성해야 함)
정책관리(분류)
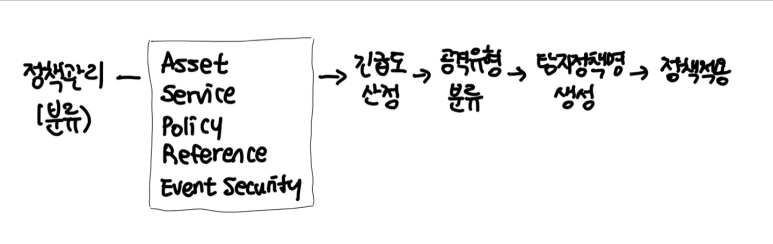
- 긴급도를 선정해야 함
- 공격유형을 분류해서 중요도 확인
- DDoS , 악성코드, 웹해킹, 비인가접근, Scan, 기타 이런 식으로 분류해두고 있음
정책관리 최적화
- 정오탐 분석
- 직접적으로 공격을 받아 올라온 내용을 분석해서 IDS, IPS에 입력하거나 공격자 IP를 방화벽에 입력해두거나 방화벽에 임계치 값을 검토해 설정해보는 것과 같은 정책을 생각해 봐야 함 (서비스 영향도 고려)
- 탐지 정책 기간은 3-6개월
- 방화벽은 보통 5-6년 정도 사용함
- 3년 이상이 되어가며 노후화가 되어가는 방화벽들은 퍼포먼스를 생각해봐야 함
- 하루에 많으면 1000-2000개의 IP를 차단하게 되는데 평균적으로 1달에 15000건이 되는 것인데 6개월이면 9만 건이 되는 것이고 그만큼의 차단 IP와 URL이 쌓이게 되면 그만큼 퍼포먼스가 떨어질 수 있기 때문에 일정 기간을 두며 정책을 삭제하고 다시 생성하는 작업이 계속되는 것
- 오탐일 경우 룰을 수정해서 정탐이 많이 발생할 수 있게끔 해야하는데 예외 처리를 해야하는 경우도 있음
- 예시 : IPS를 patch함 근데 IPS 안의 룰들이 환경에 맞게 활성화 혹은 비활성화 되어있음 근데 Patch하며 모든 룰들이 활성화가 되어버림 그럼 난리남 이게 OS 업데이트와 맞물리게 되면 관제센터가 난리남 뜯어보면 전부 MS 제품으로 접근된 것인데 공격으로 의심되게 됨 따라서 꺼달라고 요청하게 되는데 원인 파악을 우선적으로 하기 때문에 로그들이 쌓이게 됨 그래서 SIEM에서 예외처리 후 올라오지 않도록 하는 등 임시조치를 취해야 함 이런 일이 순간적으로 일어나게 되면 당황스러움 본사라면 그래도 바로 연락하고 조치가 되는데 지사가 된다면 소통의 시간이 느리기 때문에 답이 없는..
- 따라서 효율성 있는 관제가 이루어지도록 하는 것이 중요하다고 보고 있음
침해예방
- 모의 훈련
- 해킹 메일
- 시나리오 작성: 메일 제목 선정
- DDoS
- HP/중요도 높은것, 네트워크 서버 쪽
- 보안 장비 tag → 모니터링 캡처 필요
- 침해사고 (도상 훈련)
- 훈련 통제 팀: 보안 담당자 또는 시스템 담당자에게 훈련 상황 주고 대응책 내놓아라
- 상급기관 대응훈련
- 해킹메일, 침해사고, DDoS, 서버 해킹 전부 훈련
- 정보 공유
- 보안뉴스, 신규 취약점, 대외기관 정보, 기관/베더 요청사항
보안운영
- 보안 운영 인력이 있으면 보안 운영 인력이 담당하지만 있다하더라도 관제 인력의 일부는 해당 됨
- 장애 관리
- 장애 분석, 재발방지 대책 수립
- 야간 공휴일 장애 발생 시 PM에게 보고 → 비상 연락망 가동 → 장애처리 완료
- Time Table 작성
- 장애 발생 시간, 누구에게 보고, 엔지니어와 유선 연락, 조치 후 종료 시점
- 작업 관리
- 작업 계획 수립, 작업 수행, 작업결과 보고서 작성
- 이력 관리 중요!
- 보안 설정
- 백업 관리! 시스템에 들어가서 확인
보안운영 (장애관리)
- 장애 인지/ 접수 시 엔지니어에 현상을 말할 것인데 엔지니어가 증상을 확인하고 조치방법에 대해 알려주면 이게 비상조치(긴급 조치)의 방법이 되는 것
- 잘 알아두면 나중에 동일한 증상 발생 시 긴급조치 할 수 있게 됨
- 비상조치 매뉴얼이 있는 지 확인해보기
장애관리 종합
- 장애가 발생 시 특히 야간과 공휴일에 발생 시 보고를 잘 해야 함
- 비상 연락망을 갖고 유지보수 업체에 연락을 취해야 함
작업관리
- 작업 계획을 세우게 되면 상급기관에 공유를 해 줘야 함
- 보안 장비가 단절되거나 로그 수집이 안될 때 연락이 옴
- 사전에 작업계획 있을 시 미리 공유해주면 번거로움이 없음
보안관제 기술
보안관제 탐지/방어기술
- 패턴기반 탐지, 행위기반 탐지, 상관분석
- 탐지패턴 활용 - “스노트”
- 구조, port, 문자열 탐지패턴, HEXA CODE 방식 등 꼭 공부
- 스노트(Snort) : “Sniffer and more” 에서 유래 초기는 단순한 Packet Sniffer 프로그램 이였으나 현재는 분석 기능이 추가되고, 보완과 향상을 통해 지금과 같은 다양한 기능과 탁월한 성능을 갖춘 프로그램

Snort Rule 구조
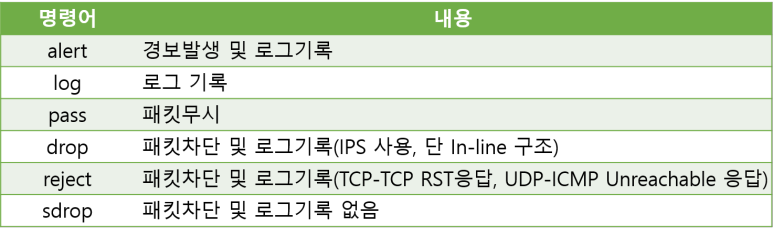
Action 유형

Protocol 유형

SrcIP/DstIP유형

SrcPort / DstPort 유형

방향지정

일반옵션

흐름옵션

페이로드 탐색 옵션
보안관제 시스템
보안솔루션분류
정보보호 시스템 종류 및 기능
- 홈페이지 APT 웹쉘공격 탐지 및 차단 시스템
- 웹쉘 및 홈 디렉터리 설정변경 탐지
- 악성코드유포지 URL 탐지
- 웹쉘 탐지 정보 및 이력 저장
- 정보시스템 서버 접근 통제 및 보안감사 시스템
- 접근통제에 의한 모든 작업 이력 저장
- 장애 및 보안사고 발생 시 사후 추적 가능
- 지능형 네트워크 접근통제 시스템 (NAC)
- 네트워크 접속 단말인증 및 무결성 검증
- 필수 S/W 설치 및 불법 소프트웨어 삭제 유도
- 위협관리시스템(TMS)
- 유해 트래픽 및 악성코드를 실시간 탐지
- 방화벽(FW)
- 침입차단시스템으로 내부 시스템을 보호하기 위해 IP 및 프로토콜 기반으로 내·외부를 접속 차단하는 시스템
- 침입방지시스템(IPS)
- 실시간 사이버 공격을 탐지 및 차단하는 시스템으로 악성코드 및 악의적인 바이러스에 대해 문자열 방식으로 탐지하여 차단하는 시스템
- 내부정보유출 방지시스템
- 사용자 컴퓨터에서 사용하는 메신저(MSN, 네이트온 등) 프로그램 사용 차단 및 이메일 송신 시 붙임 파일 용량 통제 등 내부정보의 유출을 방지 하기 위한 시스템
- 홈페이지 위변조 감시 시스템
- 악의적인 사이버 공격에 의한 홈페이지 화면 위·변조 사항을 실시간 탐지 및 웹 접속 정상 상태를 모니터링하는 시스템
- 무선랜 침입 차단 시스템(WIPS)
- 기관 내 비인가 무선 AP 탐지 및 무선랜에 대한 위협을 탐지·차단하는 시스템
- DDoS 공격대응 장비
- DDoS 공격에 대한 차단에 특화된 시스템
- 개인정보 유출방지 시스템
- 컴퓨터에서 주민번호, 여권번호 등 고유식별정보 및 중요 정보가 포함된 문 서를 식별하거나 외부유출 시 차단하는 시스템
- 웹 방화벽(WAF)
- 웹 서비스에 대한 사이버 공격 차단에 특화된 시스템
- 해킹메일 차단시스템 / 스팸메일 차단 시스템
- 악의적인 바이러스 및 악성코드 포함된 메일을 수신시에 탐지 및 차단
- 일반적인 다량의 메일 수신 및 비정상적인 메일을 수신 시 차단
- 지능형지속위협(APT)공격 대응 시스템
- 시그니처(문자) 기반의 정보보호시스템과는 달리 비정상적인 행위를 판별 하여 이상징후를 탐지 및 차단
- 매체제어시스템
- 인가된 USB 저장장치, 이동형 저장장치의 연결을 허용하고 기타 비인가된 장치에 대해서는 차단 등의 통제 시스템
방화벽
- 외부에서 들어오는 공격자 IP 사전차단해서 방지할 수 있는 하나의 보안장비
- 방화벽 정책 적용 시 최소 3번이상 확인해야 함
- 방화벽 정책 잘못 넣을 경우 네트워크가 마비될 수 있기 때문에 반드시 확인해야 함
- 방화벽의 한계는 노후화가 돼서 트래픽을 못 견디는 상황이 되면 차단되기 때문에 마비가 됨
- 사전에 검토해서 장비를 바꾸거나 다른 방법을 만들어야 함
- 당장 방화벽을 바꾸지 못하는 경우, IPS를 앞단에 넣어 필터링을 하고 방화벽에 필터링 된 것을 받게 할 수 있음 또는 SIEM에 유해 IP/URL을 입력해두고 사전에 입력해 둔 정책에 의해 올라오게 되면 해당되는 IP와 URL을 방화벽에서 차단하게하는 경우가 있음
- 이렇게 성능이 떨어지게 될 경우 위치를 바꾸거나 SIEM을 활용할 수 있어야 함
IDS/IPS
- TAP : TAP : 장비를 넣어서 트래픽을 검사하는 것
- 문제 생기면 케이블만 바로바로 바꿔 끼면 되는 것
- 스위치 미러링 : 복사본 만들어서 확인하는 것인데 문제가 생기면 장비 자체를 교체해야 함
- 장애 발생 시 By-Pass로 네트워크 상에서 문제 없이 inbound outbound 되게 하는 것인데 이것은 최후의 방법
DDoS 대응 솔루션
- 맨 앞 단에서 DDoS 장비가 작동함
- 네트워크 대역폭에 맞게 장비가 들어가야 함
- DDoS 공격이 들어오면 앞단에서 다 막아줌
- 네트워크 장비가 1G라고 가정했을 때 앞에서 공격을 다 막아주지만 다른 사람들의 트래픽이 처리가 안돼서 느려지게 됨 그래서 금융권같은 경우는 10G로 많이 되어 있는데 요즘은 또 이 공격이 10G까지도 들어오는 경우가 있음
- 서비스를 원활하게 제공하기 위해 ISP 업체 (SKT, KT, LG U+)에 서비스를 제공 받음
- 비정상적인 트래픽은 떨구고 정상적인 트래픽은 다른 경로로 우회시켜서 서비스에 영향받지 않도록 하는 대응 기법
- ISP 업체에서도 DDoS 관제가 진행됨
웹 방화벽
- OWAST 10 공격을 대부분 웹 방화벽에 적용함
- 웹 방화벽 갖고 거의 대부분 차단이 되지만 1차적으로 웹 방화벽이 있고 2차적으로 시큐어코딩을 진행해 공격을 받더라도 영향이 없게끔 강화가 됨
- 민감정보도 같이 확인해주고 있으나 오탐의 케이스가 많음
- SSL 복호화 연동 : 웹 방화벽이라고 해서 암호화된 공격을 탐지해주는 기능이 100% 적용이 되는 것은 없음 지금까지는 웬만한 것들은 웹 방화벽에서 탐지해주지만 암호화되면 숨기고 들어오는 것이기 때문에 모르는 경우가 많음
- SSL 장비를 갖다 놓고 벤더사에서 확인해서 복호화되어 탐지될 수 있게끔 해주는데 비용이 상당히 셈 인바운드와 아웃바운드 각각 2개 씩 들어가야 탐지 되므로 총 4대가 들어가는 것이기 때문에 비싼데 이렇게 보안하기를 원하는 경우가 있음
- 웹쉘탐지 솔루션 : 웹 방화벽 있어도 웹쉘이 올라가 있는 것을 탐지 못하는 경우가 있고 알려지지 않은 웹쉘이 있으면 그것을 탐지할 수 있게끔해야 함
- 탐지하고자 하는 URL을 등록해서 라이센스 구입하는 것
NAC
- 네트워크 진입 시 단말과 사용자를 인증하고, 네트워크를 사용중인 단말에대한 지속적인보안취약점 점검과 통제를 통해 내부 시스템을 보호하는 네트워크 접근제어 솔루션
Anti-Virus
- 바이러스 백신 소프트웨어는 바이러스, 웜과 같은 악성 소프트웨어 프로그램을 검색, 방지, 해제 또는 제거하는 컴퓨터 프로그램
기타 보안 솔루션
- 안티 랜섬 : 초창기에는 여러 파일이 한 번에 삭제될 경우 차단해버리는 일이 많았음 이후에 업데이트 되면서 바뀌었지만 최근엔 많이 사용되지 않음
실습 - 보안담당자 입장에서의 대응방안 작성
1) 물리적 망분리로 보안 강화 및 사용자 PC에 anti-ransomeware / virus 설치, 업데이트
2) APT 탐지 솔루션 운영
3) 중요 정보 및 개인정보 유출을 대비하여 중요 정보가 있는 파일 취급 시 파일 압축 후 암호 적용과 내용에 대한 암호화 (DRM) 솔루션 적용
4) 기사에서 언급된 메일주소 스팸 브레이커 장비에 차단 적용
5) 중요정보 유출에 대비하여 DRM 적용 검토
6) 랜섬웨어 피해감소를 위해 파일 백업(이중화 포함) 또는 중앙관리 여부 검토
7) 이메일을 통한 랜섬웨어 감염 예방을 위해 사용자는 출처 불분명한 메일은 열람 및 첨부파일 실행 금지에 대한 습관이 필요
보안관제 실무
보안관제센터
- 관제센터는 제한 구역임 아무나 들어갈 수 없음
- 상시 출입할 수 있는 인력들이 있음
- 사람이 바뀔 시 항상 리스트를 갱신해서 걸어두어야 함
- 외부 출입자 출입 시 출입자명부 작성해야 함
- 퇴직자 보안 서약서 작성
- 신원조회도 해 봄
사업수행 업무
- 보안관제 : 실시간 모니터링, 탐지 룰 개발, 이력관리 및 최적화, 훈련 지원
- 모의 훈련 수행 : 자체 모의 훈련 수행 및 지원
- 취약점 점검 및 모의해킹 : 취약점 점검 수행 및 이행점검
- 정보보호 시스템 운영 : 인력이 별도로 있을 시 해당 업무 진행, 없으면 관제가 일부 시행
- 정보보안 관리 : 매뉴얼 최신화, 기술 검토 지원, 교육 및 인식 제고 활동
- 사업 관리 : 보안관리, 교육, 서비스수준관리, 진도 관리
훈련지원
- 훈련 계획 수립하고 인력 계획해서 수행해 본 후 제대로 되는 지 임계치 설정하고 보고서 작성하는 것
- 전산망 침투는 실제로 침투되었는 지 안되었는 지 확인해보고 결과 보고서 작성하는 것
정보공유
- 정보 수집 및 정보 배포
산출물
- 정기보고
- 일일보안 관제보고서 : 대응 현황
- 월간, 분기 실적 보고서
- 연간보고서
- 수시 보고
- 사이버침해 분석 및 대응 보고서 : 정책 설정 신청성, 정책 이력관리대장, 상황전파문
- 매뉴얼 지침 재개정
- 기타보고서 : 월별휴가계획서
일일관제보고서
- 시스템 운영 현황 : ESM 또는 SIEM, 각 보안 장비 이상유무 현황
- 스팸, 피싱 메일 수신 현황
- 보안뉴스, 취약점 권고문
침해사고 분석 보고서
- 정말 침해사고가 발생했을 때 cert팀이 나가 대응한 내용을 작성한 보고서
- 관제 시 사고 발생했을 때 피해서버의 정보와 장비 정보를 포함해야 하고 공격자 정보를 작성해줘야 함 또한 언제 처음으로 공격이 들어왔고 언제까지 공격이 들어왔는 지 방화벽, IDS/IPS 찾아서 Cert 팀이 분석 보고서 작성 시 내용 전달해 줘야 함
비정상 트래픽 티켓팅
- 티켓이 올라오면 이벤트 분석하고 정탐 시 해당 담당자에 메일 발송하고 담당자가 회신을 하면 티켓팅의 처리 절차가 되는 것
- 단위보안 장비 -> 로그 수집 -> F/W 차단
- 티켓팅 처리 상세 (경보발생) : 어느 장비에서 언제 경보가 올라왔는 지 알게 됨
- 티켓팅 처리 상세(Raw Data 분석) : 패킷 내 Raw 데이터를 기반으로 정/오탐을 판단하여 실제 공격으로 확인될 시 외부 FW에 공격 IP 차단
- 티켓팅 처리상세 (공격자 IP 평판 검색) : 평판조회 사이트 참고하여 유해 IP 여부 활용
- 티켓팅 처리상세 (유해 트래픽 분류) : 공격 유형 분류하여 이력관리 함
- PHP 관리자 페이지 접근시도, RDP 접근시도 (3389 포트)
- 디렉토리 비정상 접근 - URL
- 입력값 검증 필요
- SQL Injection - raw data에 다 나옴
- 이벤트 분석 보고서 - 특이한 케이스가 나왔을 경우 (관제 측면에서)
실습 - 공격 유형 중 한개 선택해서 보안관제 시 탐지된 이벤트에 대해 시스템 담당자에게 조치 요청 사항 작성
대상 기관 담당자에게 이벤트 발송
발생일시: 2024.04.15 17:09
이벤트명: SQL-Injection /XSS
공격자 정보: 111.11.11.11 (국적): 1234
목적지 정보: 222.22.22.22 (시스템명): 80, 443
공격 Raw data
‘=0’, ‘1=1’
공격 영향도 설명
만일 공격에 의해서 침해사고가 발생했을 경우 반드시 네트워크 절체
분석팀 분석 완료 시까지 포맷 금지
요청: 소스코드 대상 시큐어 코딩으로 취약점 제거
통합보안관리시스템(ESM)
- 관련 기능이 전부 들어가 있따고 보면 됨
- 모든 기능을 사용하지는 않음
- Reporting : 이것도 참고 할만한 사항만 하는거지 자동으로 만들어주지는 않음
- Agent를 통해 로그가 로그서버로 수집되고 수집 서버에 있는 로그를 RM 서버가 참고해서 스스로 분석해서 각각의 보안 장비에서 이벤트가 올라오면 실제로 화면에 들어가게 되는 것
- 사이버위기단계 (경보단게) : 임계치 조정 가능
- 관심단계에서부터는 필요시 대기까지 함
- 국정원이나 금융 보안원에서 사이버 위기 단계 관리해주고 상황 전파문 내려옴
- 사고이관(사고접수 할당) : 이벤트에 관한 내용 다 확인 가능
- 보안 권고문이나 보안 뉴스를 발제하면 전부 공유하고 ESM에 접속할 수 있는 권한 가진 사람들은 다 볼 수 있음
네트워크 보안
기본 원리
- 패턴매칭
- 이상징후 분석
컴퓨터의 시작
- Bombe 와 Eniac
- 세계 2차대전 독일군 암호 해독을 위한 기계장치
- 세계 2차대전 탄도 계산을 위해 만들어진 계산기계
네트워크의 시작
- 1960s
- Arpanet : 컴퓨터들을 네트워크로 묶어보기 위한 시도
- 이게 발전해 현대의 인터넷이 된 것
운영체제의 시작
- 1970s
- Unix : 캔 톰슨
- C언어 : 베니스 리치
- 이전까지 컴퓨터는 암호를 해독하거나 탄도 계산하는 등 특수목적을 위한 기계 장치였음
- 극소수의 사람들만 활용했음
- 그러나 이 두 사람의 활약으로 활용도가 넓어지게 됨
해커의 시작
- 1980s
- 케빈 미트닉 : 국가 중요 기관 및 대기업 해킹
- 로버트 모리스 : 웜 바이러스 최초로 퍼뜨린 사람
- 클리포드 스톨 : 본업은 천문학자인데 연구소의 컴퓨터를 직접 관리했음 예전에는 모뎀을 이용했는데 모뎀으로 전화선도 사용함 전화세가 갑자기 많이 나와서 추적해봤더니 이사람이 해킹 한거(?)
해킹 사례
- KT 고객정보 유출(2014) : 파로스라는 해킹 툴 언급됨 (웹 프록시 툴)
- 아이핀 부정발급(2015) : 파라미터 위변조 수법 이용됨
- 코레일 타인 게시글 노출(2016) : 타인게시글 노출
- T-모바일 고객정보 유출(2017) : 전화번호 입력받는 변수를 바꾸면 전화번호 주인의 개인정보 유출 됨
파라미터
- 파라미터가 바뀌면 정보도 바뀐다
- URI = URL + 변수
- URL = 경로 + 파일
- 버프스위트 활용

이걸 잡으면
s = home
s 값 변조

결과
보안의 시작
- 해외 : 모리스웜(1988)
- 국내 : 1.25대란(2003)
- 국가단위에서 해킹 예방이 필요하겠다고 생각하게 된 계기가 됨
보안 업무 비중
- 백신을 기본으로 깔고 간다고 생각했을 때 방화벽과 IDS/IPS가 많이 쓰임
- 전부 네트워크 보안장비들
- 미국 통계에서도 네트워크 모니터링, 방화벽, UTM, IDS를 가장 많이 사용한다고 되어있음
- 미국의 트랜드를 전세계가 따라가기 때문에 어쩌면 당연한 것
네트워크보안 장비를 많이 쓰는 이유
- 네트워크의 물리적 제약이 적어서 그만큼 해킹이 쉬움
- 피아식별이 어려워서 방어가 어려움
- 모든 노드를 감시하는 것보다 모든 데이터가 지나가는 골목을 감시하는 것이 효율적이기 때문에
방화벽
- 체크포인트 Firewall-1 (1994년)
- 최초의 네트워크 보안장비
- IP/Port 기반으로 동작
- 허용 정책에 포함되지 않는 모든 IP/Port 차단
보안에 취약한 웹서비스
- www.yahoo.com (1995년)
- 방화벽이 차단할 수 없는 웹서비스 등장
- 웹 해킹 등장
IDS(Intrusion Detection System)
- IP/Port 상위개념의 접근제어 필요성 대두
- 애플리케이션 레이어의 데이터 패턴을 검사하는 snort(1998년)
- 패턴매칭 : 어떤 문자가 쓰였나 확인 (보안에 관련되었는가)
- 방화벽은 편지봉투만 보는 것 IDS는 편지내용 보는 것
패턴매칭
- 인류가 경험한 가장 효과적인 데이터 수집/분석 방법
- 도청은 인류가 역사적으로 효과가 검증된 데이터분석 방법임
- 이런 방법을 자연스럽게 컴퓨터 보안에도 적용된 것
- 특징
- 주고받는 패턴으로 상호관계 파악 가능
- 사람과 똑같은 방식으로 소통하는 것이므로 주고받는 패턴으로 정상 비정상 파악 가능
침입탐지 모델
- 패턴 매칭(오용행위분석) : 정해진 패턴을 갖는 공격만 막음
- 공격 정의가 쉬움 (이미 발생한 것이므로)
- 알려지지 않은 공격은 못 막음
- IDS/IPS(Black List)
- 이상징후(비정상행위 분석) : 정의된 패턴을 갖는 정상만 허용
- 정상만 정의하면 됨
- 정상 범위를 정의하기 어려움
- 방화벽, 웹방화벽 (White List)
- 오용(공격) 패턴을 찾는 패턴매칭 중심으로 발전
- 이상징후 분석 일부 수용(패킷 임계치 초과 트래픽 탐지 등)
패턴매칭의 장점
- 쉽다
- 개발이 용이하며 개념적으로도 패킷에서 패턴을 찾는 것이 더 이해하기 쉬운 방법
- 검사 범위를 좁힐 수 있다
- 네트워크 트래픽 > 패턴 필터링 > 위협의심로그
- 네트워크 보안 기반 기술이 됨
- WAF, IPS, IDS 모두 패턴 매칭을 깔고 있음
패턴 매칭의 오탐 문제
- IDS에는 시장에서 실패했다는 보고서가 나온 적이 있음
- 그 이유는 오탐
- 1988년 Haystack 프로젝트에서 대량의 데이터에서 하나의 특정 오탐이 건초더미의 바늘을 찾는 거 만큼 어렵다고 말함
- IDS가 경보가 너무 많이 발생해서 좋지만 부담스러움
- 수십만, 수백만 라인의 로그를 꼼꼼히 확인해야 함
검사 범위 좁혔는데 오탐 로그가 왜 많을까?
- 도청이 성공하려면 타겟이 뚜렷해야한다
- 네트워크의 특징이 피아식별 어려움이므로 누가 공격자인지 몰라서 모든 것을 검사해 너무 많은 것
- 트래픽의 특성 : 수십개 수준의 문자 기호로 수십만 이상의 문자열 조합 가능
- 뉴스 기사 제목을 생각해보면 자극적인 키워드만 나열하고 내용은 아닌 경우가 많은 것처럼~~
- 네트워크 보안 실무(2004, 미국) : 대량 경보, 잘 만들어지지 않은 IDS시그니처
- IDS와 보안과제의 완성(2013, 한국) : 룰 정확도 향상이 이루어지지 못하면서 부정확한 로그가 대량 발생
- 따라서 보안 장비를 범용적 rule을 현장에 맞게 customizing 필요 “룰 최적화” 필요
보안관제 업무 프로세스 (IDPS)
- IP/ Port 관계 분석 : 발생 가능한 포트로 들어온건 지 확인 or 외부에 오픈한 적 없는 port로 들어왔는 지
- Raw Data 분석 : 단방향 패킷 하나만 가지고 분석
- 트래픽 로깅 분석 : 양방향 패킷들로 분석 (들어오고 나간 트래픽 수집)
- 정탐 여부 확인
SNORT
Virtual Box 설치 (버전 확인)
https://download.virtualbox.org/virtualbox/7.0.14/VirtualBox-7.0.14-161095-Win.exe**

- 파일 > 가상 시스템 가져오기 > cent os 7 이미지 (sk.zip > tool > os_image >centos7.ova )
- 가상머신 네트워크
- eth0(NAT)로 외부 네트워크와 연결 : 실제 PC와 연결된
- eth1 가상 네트워크 연결 (내부망)
- 가상 머신 실행 후 putty에 접속하여 id,pw 로그인
- 스냅샷 - 초기 이미지 저장


리눅스 원격 접속
- pscp.exe

- putty 설정 : 강의자료 참고 (host ip address : 192.168.56.100)
SNORT 설치 (로그인한 후, putty에서 명령어 실행)
- snort 설정
- /usr/sbin/snort (실행파일) -> /etc/snort/snort.conf (설정파일) -> /etc/snort/rules/local.rules (룰파일)
- snort.conf 설정

511,512

521

548-651 주석처리
- 룰파일 만들어주기
- snort 실행모드
- 경고/패킷 데이터 분리
--> snort -i eth0 -c /etc/snort/snort.conf -A fast (IP 헤더 수준 기록)
--> snort -i eth0 -c /etc/snort/snort.conf -A full (프로토콜 헤더 수준)
--> snort -i eth0 -c /etc/snort/snort.conf -K ascii (출발지별 프로토콜 헤더 수준)
- 즉, 파일보다 명령어가 우선된다는 것
- 경고/패킷 데이터 통합
--> snort -i eth0 -c /etc/snort/snort.conf (unified2 설정)
- 탐지테스트

내부망 감지테스트
mysql8.0 설치(putty창에서)
- my sql 패스워드 정책 변경
- mysql 패스워드 및 접속 권한 변경
- 윈도우에서 DB 접속을 위한 툴 설치
- SQLog61.exe
--> host는 192.168.56.100 하고 비밀번호 입력해서 connect
barnyard2 설치
- Snort가 사용할 DB를 만들어줘야 함

설치 및 압축 해제 확인
임시파일생성

DB생성 확인
- DB 연동 설정 수정

barnyard2.conf
- barnyard2 설정 : /usr/local/bin/barnyard2 (실행파일) -> /etc/snort/barnyard2.conf (설정파일) -> /etc/snort/sid-msg.map (설정파일) -> /etc/snort/rules/local.rules (룰파일)
- map파일이 중요 룰파일과 연동되어있어야 함
- SNORT 스택 : 트래픽 -> 전처리기 -> 병렬 패턴매칭(Aho-Corasick이라는 패턴매칭 알고리즘 이용) -> 룰 패턴매칭
- 병렬패턴 매칭: 일종의 패턴 그물을 만들고 걸린 애들만 가지고 룰 패턴 매칭 (좀 더 빠르게 수행)
- 로그 생성되면 barnyard2가 읽음
- barnyard -> mysql 이걸 만든 겨
- snort와 barnyard 연동 다시 확인
- barnyard2 실행 : arnyard2 -c '설정파일' -d '로그파일 경로' -f '로그파일' -w '임시파일'
- 예시 : barnyard2 –c /etc/snort/barnyard2.conf –d /var/log/snort/ -f alert.log -w/var/log/snort/barnyard2.temp
- barnyard 실행시에 임시파일을 일일히 지정하지 않아도 되도록 설정
- 로그 파일 생성 확인
SNORT.OVA
- cent OS에서는 alert.log가 안만들어지므로 DB까지 정상 구축되어있는 이미지인 snort.ova를 불러와서 다시 설정해주기
- putty > host ip address : 192.168.56.101
- /etc/snort/snort.conf 확인

101확인
- 임시파일 생성
- /etc/snort/barnyard2.conf 확인
- barnyard 실행
waiting for new data!!!!!!!!!!!!!!
- 정상 연동 확인
- barnyard 실행시킨 채로, 새 putty 창에서 /etc/snort/rules/local.rules 확인
- rule 하나 존재 -> sid, name 정보와 똑같은 것이 /etc/snort/sid-msg.map에 저장되어 있어야함
- 동기화 제대로 되어있어야 함

아유 잘 굴러간다
- 데이터베이스 확인
SQL
Structured Query Language
- 데이터 조회 및 가공 등에 사용하는 구조적 질의 언어
SQL 기본구조
- select : 어떤 필드를 보겠다
- from : 어떤 테이블에서 보겠다
- where : 어떤 조건으로 보겠다
- 예시) select 성명 from student where 학번=11
- student 테이블에 학번이 11인 성명을 보겠다
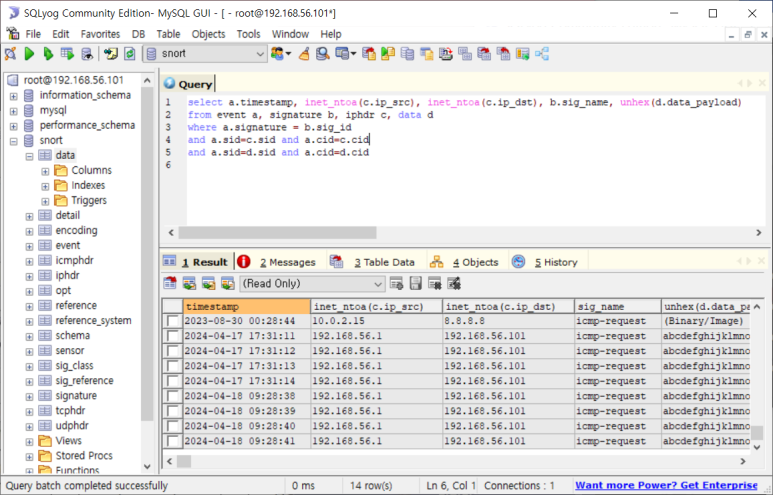
Snort 스키마
- 주요 테이블/필드 내역
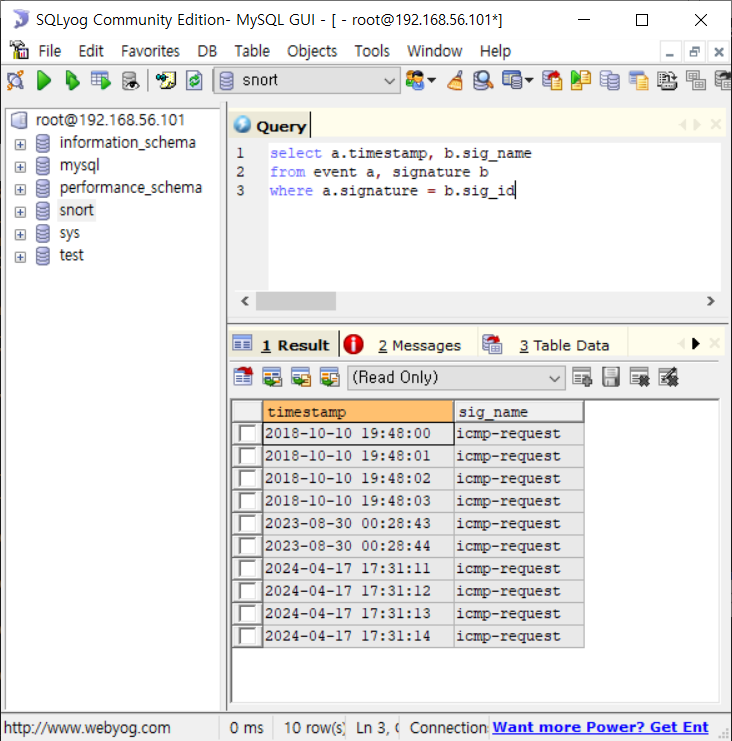
- event테이블은 실시간 로그 기록 테이블임
--> timestamp(발생시간)와 signature(룰 일련번호)
- signature 테이블은 룰 일련 번호 정보
--> sig_id(룰 일련번호)와 sig_name(룰 이름)
- event와 signature 테이블 조인해서 봐야할 때 동기화 필드 : signature = sig_id

- 쿼리문 작성해서 봐보기
- 별명 설정
- 너무 길어서 단순하게 사용하기 위해 별명을 설정해 줌
- IP 정보 추가
- sid : 탐지센서 (여기서는 랜카드)
- cid : 로그의 일련번호 (로그가 저장되는 순서대로 매겨지는 번호)

- 패킷 데이터도 함께 봐보자
- 16진수로 변환하고 뭐 그렇게 보기 편하게 바꿔보자
SNORT 룰
룰
- 헤더 : 트래픽 발생 주체 및 방향 정의
- 옵션 : 트래픽 세부 특징 정의

룰 옵션
- 패킷 헤더(물리적 특성) 및 페이로드(내용) 정의
- 패킷 헤더를 검사하는 옵션과 payload를 검사하는 옵션이 있음
- Payload는 문자열을 검사하는 것이라고 보면 됨
권고사항
- payload 검사 옵션보다 header 검사 선행할 때 성능향상에 유리
- alert tcp any any -> any any (패킷헤더(non-payload)검사 하고 payload 검사)
패킷 헤더(Non-Payload)검사 룰 옵션
- http://manual-snort-org.s3-website-us-east-1.amazonaws.com/node33.html
- 패킷 헤더의 물리적 특성을 이용한 검사
- flow : 트래픽 방향 선택(SYN 플래그 기준)
- flowbit : 세션 추
- flags : TCP flag bit 검사
- dsize : 페이로드 사이즈 검사
- to_server : to_SYN 플래그 수신자 (from_client와 동일)
- to_client : to_SYN 플래그 송신자(from_server와 동일)
- established : 세션 수립 후
- not_established : 세션 수립 전
flow
- 단점 : Client<-> Server 구분이 명확한 네트워크에서만 사용 가능
- 외부에 여러 Client가 있을 경우 잘 안됨
- 예시) flow:to_server;content:"aaa";
- TCP SYN 플래그를 수신한 서버로 향하는 트래픽만 검사
flowbit(세션 추적)
- content:"securecrt.html";flowbits:set, '세션이름'; flowbits:noalert;
- content: "VanDyke"; flowbits:isset, '세션이름';
- 위 구문들의 의미는 securecrt라는 html이 있으면 세션이름으로 라벨링하고 라벨링 된 트래픽 안에서 VanDyke를 탐지하겠다
- 양방향 검사 시 유용하지만 성능을 잡아먹음
- snort가 지원하는 옵션이고 현장에서 잘 쓰이지는 않음
- 복잡한 룰 사용할수록 장비에 장애가 발생할 수 있기 때문임
- 예시
Flags(TCP 흐름제어 검사)
- 옵션

- syn 플래그는 처음 세션 만들 때만 쓰임
- 실제 데이터 송수신이 발생하지는 않음
- 좋은 예시 : flags:S; content:”aaa”;
- 나쁜 예시 : content:”aaa”; flags:S;
- 헤더가 뒤로 왔으므로
- 더 나쁜 예시: content:”aaa”; flags:PA;
- 문자열을 검사한다는 것은 데이터가 송수신될 때를 검사한다는 것인데 puch ack는 가장 빈번하게 발생하기 때문에 PA가 더 나쁜 예시라는 것
Push + Ack
Dsize(Payload 사이즈 검사)
- dsize: 300 ->300byte
- dsize:>300 -> 300byte 초과
- dsize:<300 -> 300byte 미만
- dsize:199<>301 -> 200 ~ 300byte
- 전체 사이즈가 아닌 순수하게 데이터 사이즈만 검사함
Threshold(패킷 발생량 측정)
- 특정 발생량 발생하면 검사하겠다
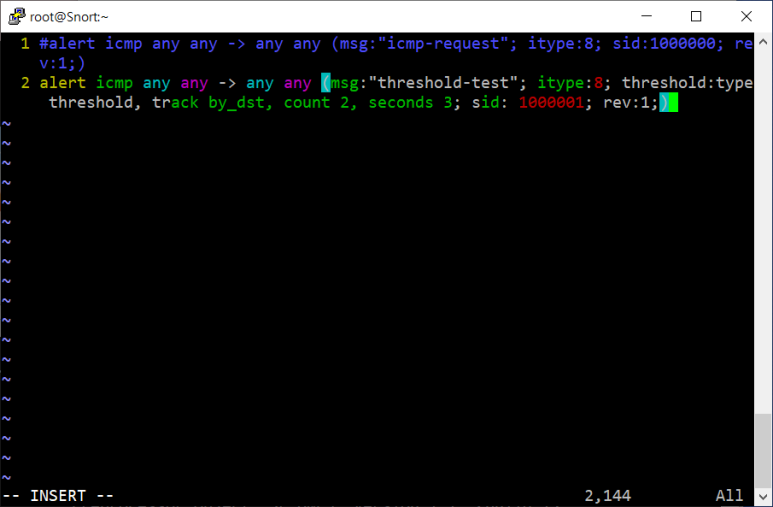
- 옵션 유형
- threshold : 패킷 임계치(임계 시간 무시)
- limit : 임계 시간동안의 패킷 임계치(=발생개수)
- both : 임계 시간
- IP 조건 옵션
- track by_src : 출발지 IP
- track by dst : 목적지 IP
- 패킷 발생량 : count
- 시간 조건 : seconds
- 적용해보자
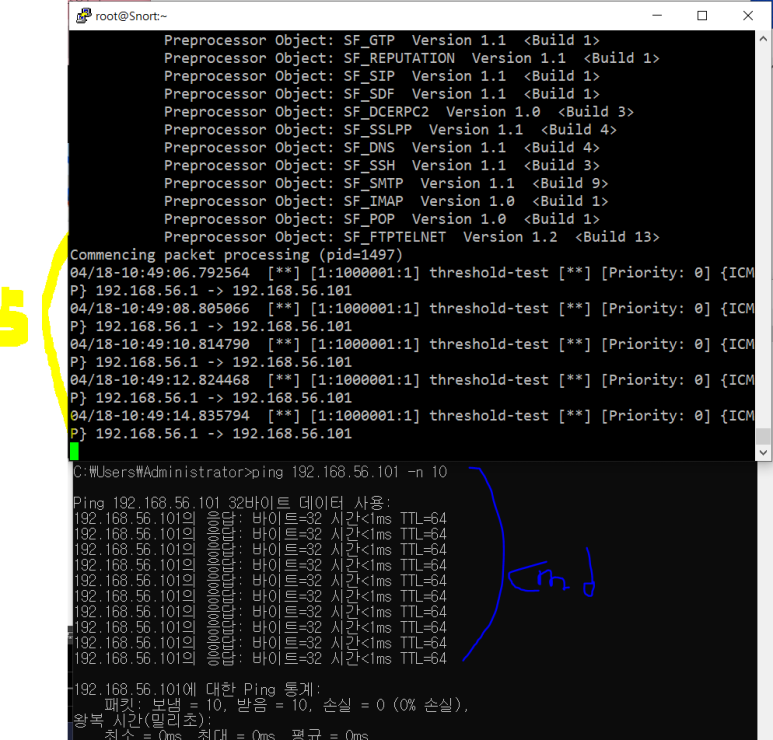
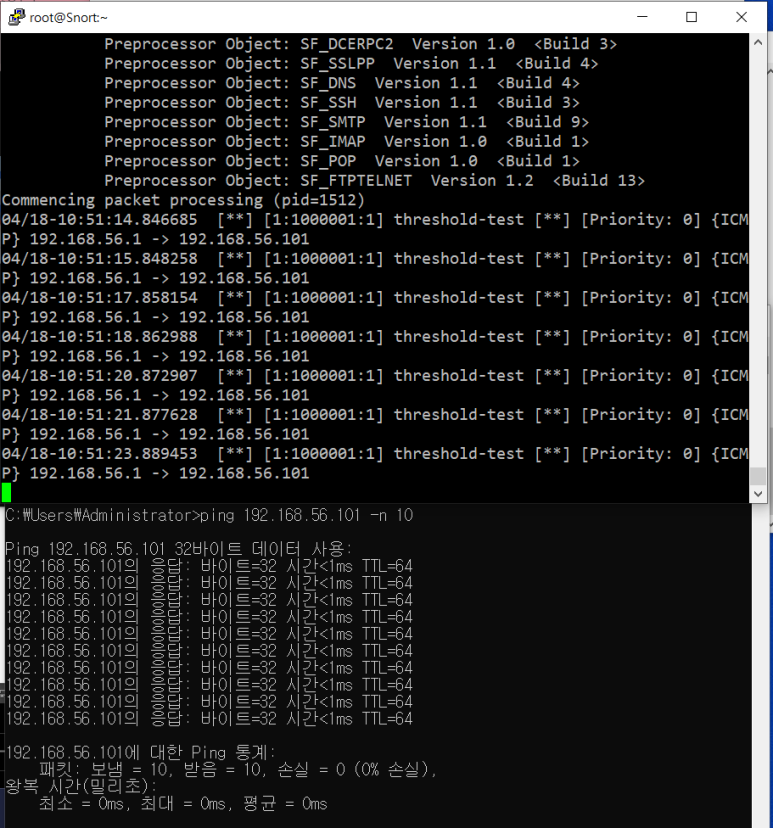
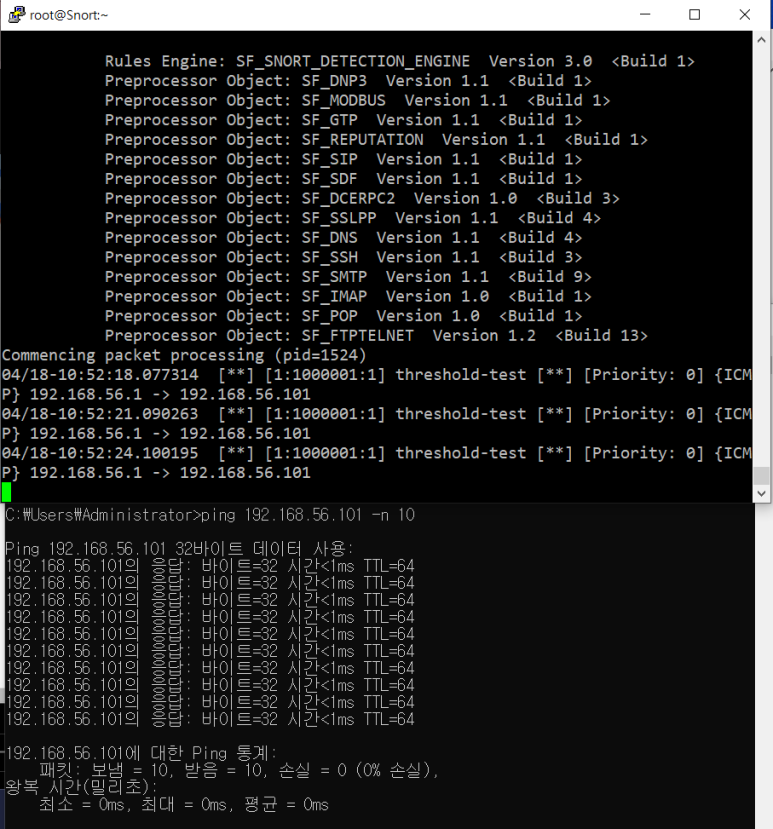
threshold 결과 -> 5개
limit 결과 -> 7개
both 결과 -> 3개
Payload 검사 옵션
- content : 페이로드 전체 (순수 문자열 검사만 가능)
- uricontent : URI (순수 문자열 검사만 가능)
- 순수 문자열 검사만 가능하다는 것은 alert(content:"a";) 이렇게 입력 시 소문자 a만 검사한다는 것
- pcre : 페이로드 전체(정규표현식 지원)
- 수정자(modifier) : content/uricontent 검사 방식, 범위 등을 수정
- nocase : 대소문자 구분 해제 alert(content:"a";nocase;)
- offset : 검사 시작 위치(절대위치)
- depth : 검사 범위(절대위치)
- distance : 검사 시작 위치(상대위치)
- within : 검사범위 (상대위치)
- fast_pattern : Aho-Corasick 패턴매칭 우선순위 조정
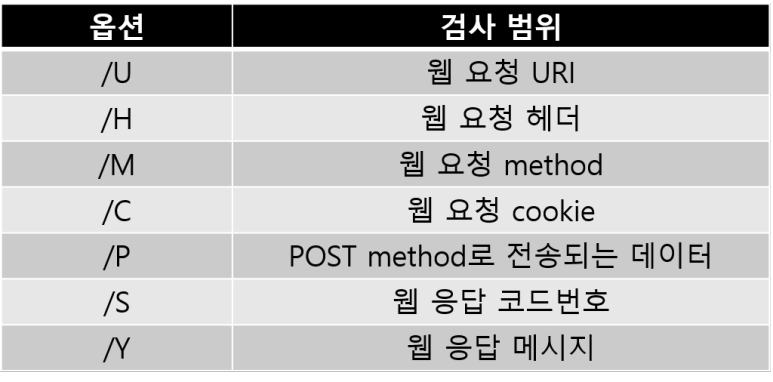
- http_uri : 웹 요청 URI (uricontent와 동일)
- http_header : 웹 요청 헤더
- http_method : 웹 요청 method
- http_cookie : 웹 요청 cookie
- http_client_body : POST method로 전송되는 데이터
- http_stat_code : 웹 응답 코드 번호
- http_stat_msg : 웹 응답 메시지
- 예시) content:“GET"; offset:0; depth:3; content:”rawdata”; distance:2; within:7;
- offset은 페이로드가 시작하는 위치니까 0바이트 이동한다는 것이므로 이동안하겠다는 뜻이고
- depth3만큼 이동한다니까 그 사이에 GET있는 지 확인하겠다는 것이고
- rawdata 검사해보겠다는 것이고 distance 주면 rawdata 검사 시작 위치 정해줄 수 있는 것임
- GET 검사하고 다시 맨 앞으로 돌아갔기 때문에
- 이전 검사 끝난 위치를 시작 위치로 삼아서 2바이트 이동한다는 의미이고
- 여기서 부터 7바이트 안에 rawdata있는 지 확인해보겠다는 의미
--> 이런 옵션 사용 안하면 모든 검사를 계속 처음부터 다시해야 하는 것이므로 성능 저하가 발생함
--> 이를 막기 위해 이런 옵션들을 사용하는 것
PCRE(Perl Compatible Regular Expression)
- 정규표현식 그 자체임
- content : 한 글자 알파벳 이름을 갖는 exe 파일 검사 시 26개의 룰 생성 필요
- content : "a.exe"; . . . content:"z.exe";
- pcre 옵션 사용하면 1개만 생성해도 됨
- prce:"/[a-z]\.exe/";
- /i : 대소문자 구분 안 함
- pcre:"/GET.*exe/i”;
- /s : 줄바꿈 문자 검사
- pcre:”/GET.*exe/s”;
- /m : 앵커 문자의 줄 구분 해제
- pcre:”/^GET.*exe$/m”;
- /R (snort only) : 'distance:0'과 동일
- content:”GET /”; pcre:”/\.exe$/R”; (GET검사 끝난 후부터 검사 이어가겠다는 의미)
- 무한 조합의 문자열을 일정한 규칙으로 표현
- 추가수정자(snort only)
Payload 검사 룰 옵션
- Wireshark 문자열 검사 옵션 'contains'
- 대소문자 구분, 정규표현식 사용 불가
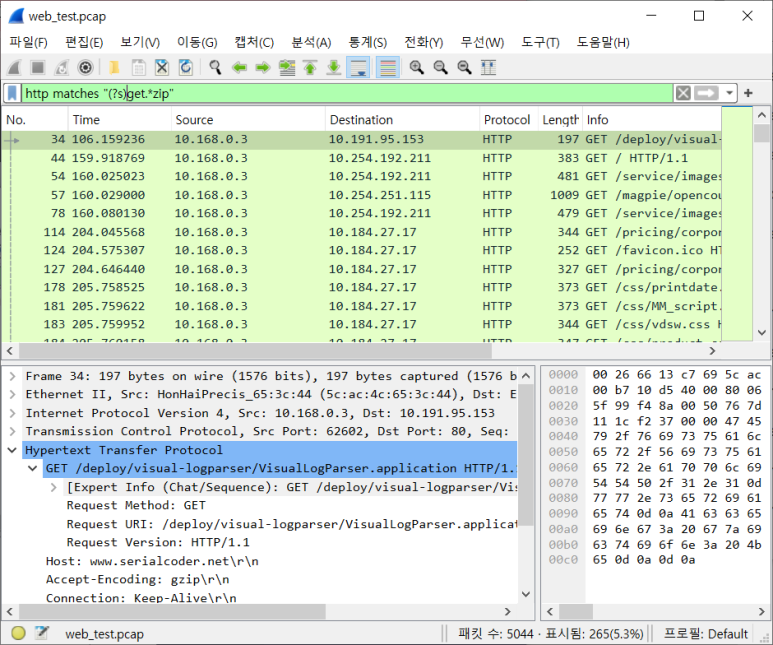
- Wireshark 문자열 검사 옵션 'matches'
- 정규표현식 사용 가능, 대소문자 구분 안함
- 줄바꿈 문자를 검사할 수 없는 상태

- 줄바꿈 문자 검사 수정자(s) 사용
- 앵커문자(^,$) 줄 구분 상태
- 앵커문자 (^,$)줄 구분해제 수정자 (m)사용
- fast_pattern(Aho-Corasick 패턴매칭 우선 순위 조정)
- 예시) content:”bb”; fast_pattern; content:”aaa”;
--> ‘bb’로 Aho-Corasick 패턴매칭 후, ‘bb’와 ‘aaa’를 순서대로 룰 패턴매칭 검사
- content:”bb”; fast_pattern:only; content:”aaa”;
--> ‘bb’로 Aho-Corasick 패턴매칭 후, ‘aaa’만 룰 패턴매칭 검사
- file_data : 이진 파일 및 BASE64 인코딩 등 텍스트가 아닌 영역까지 검사 확장

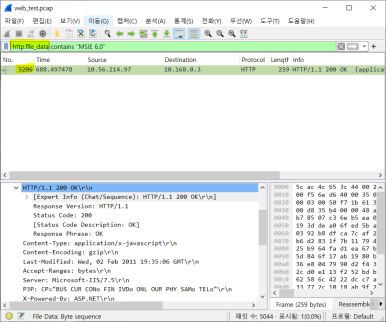
file_data에 따라 다른 패킷 나온 것 확인 가능
PCRE
정규표현식
- 메타문자 : 정규표현식의 자음과 모음
분류
- 문자열 검사
- 고정된 문자열 범위를 검사
- 가변적인 문자열 범위를 검사
- 검사(시작 또는 끝나는) 위치 검사
- 검사 방식 조절
- 검사 방식 지정(수정자)
- 검사 수량 지정(수량자)
메타문자
- 고정된 문자열 범위를 검사하는 메타문자
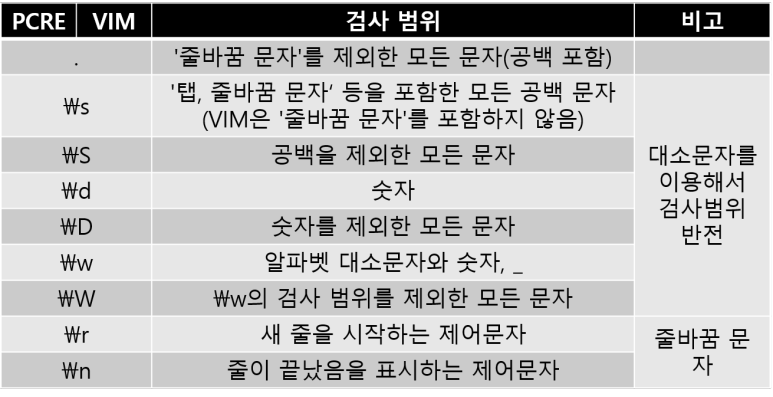

.

\s
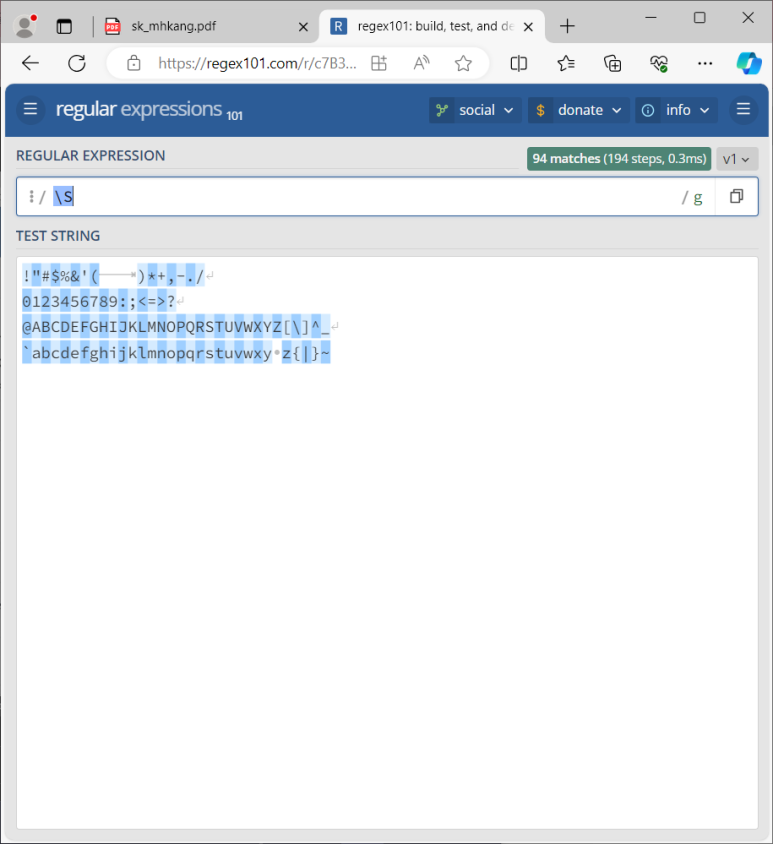
\S
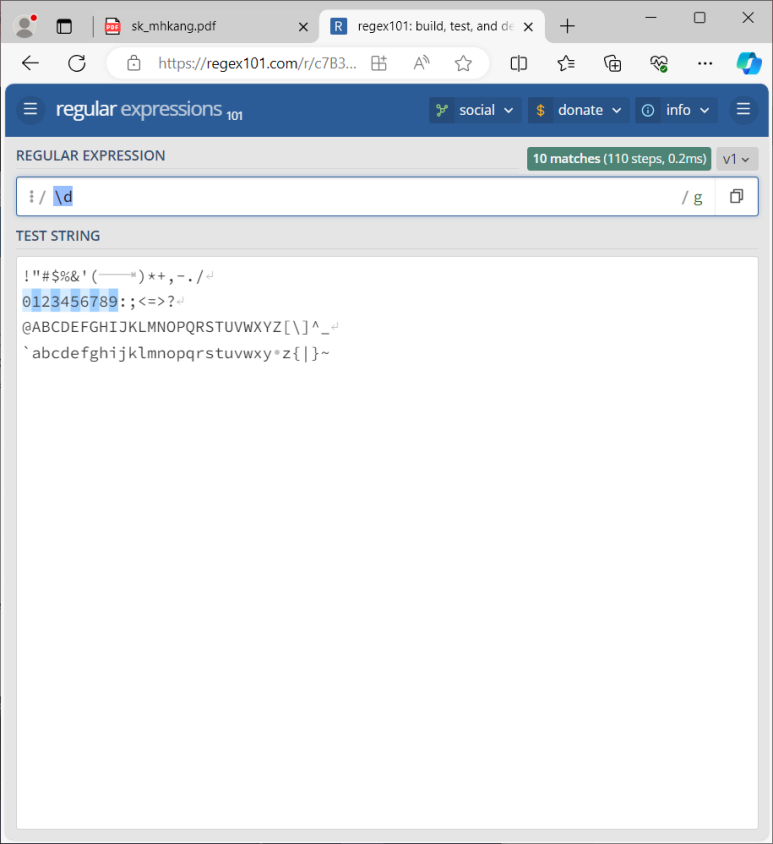
\d
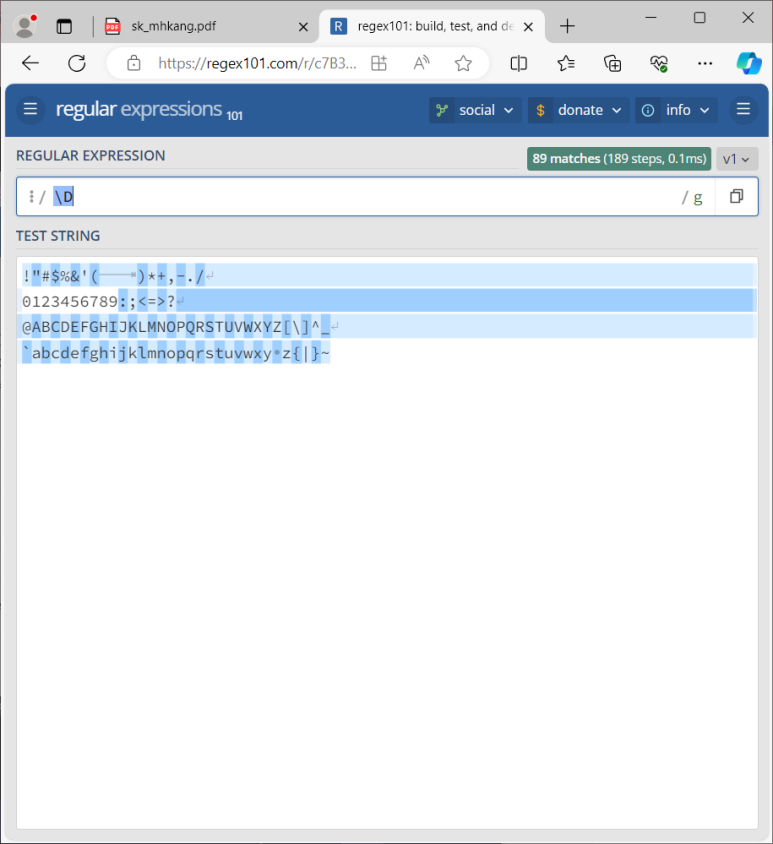

\w

\W
- 줄바꿈 문자
- 가변적 문자열 범위를 검사하는 메타문자
- 문자열 범위 지정 가능
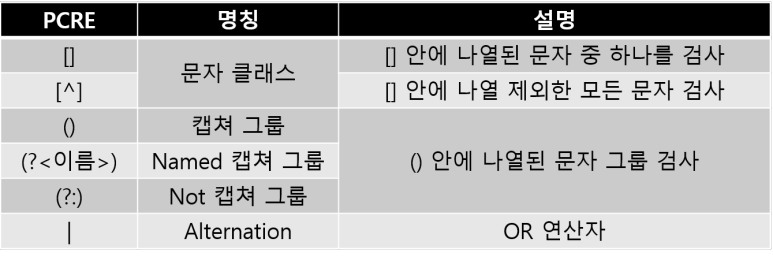
- 검사 위치를 결정짓는 메타문자

- 검사 수량을 결정하는 수량자 (Quantifier)
- 문자1 + 문자2 + 수량자(문자 2 수량 결정)
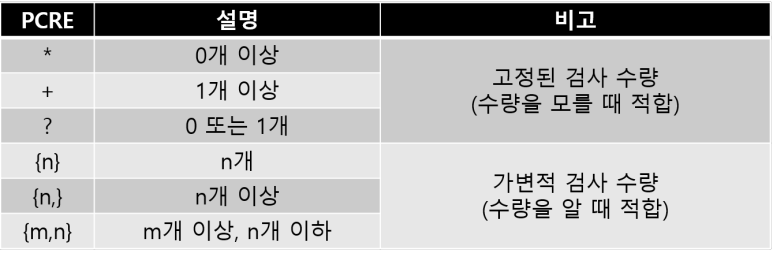
- 검사 가능한 범위를 최대한 검사하려는 특징이 있음
- 검사량은 수량자의 보조를 받는 메타문자의 검사 범위에 달려 있음
- 줄바꿈 문자를 검사하지 못하는 메타문자 .은 줄바꿈 문자 앞에서 검사를 종료
- 최대 수량 검사가 기본이지만, 검사 범위를 최소로 제한할 수 있음
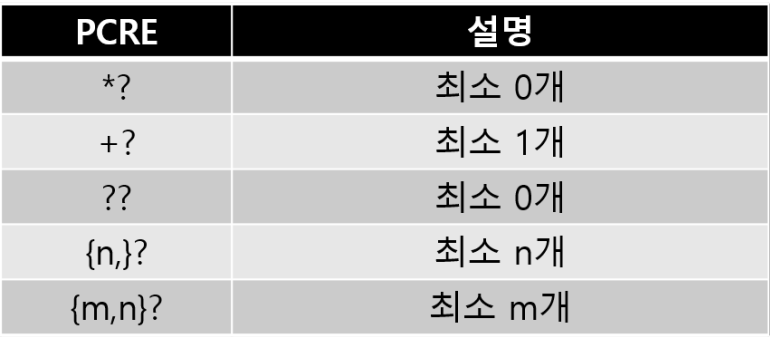
- 최대 수량 검사는 전체 검사 후 하나씩 후퇴
- 최소 수량 검사는 하나씩 검사
- 정규표현식을 잘 쓰는 방법은 이것을 외우는 것이 아니라 내가 찾고 싶은 문자의 특징을 잘 아는 것임!
PCRE 연습문제
메소드 영역만 검사하려면?
- gi 설정 : global, insensitive (대소문자 구분 안 함)
- get : 두개가 검색 됨
- ^get : g로 시작하는 것만 검색 됨
- get\s : 이렇게 빈칸까지 검색해봐도 됨
- get(?=\s) 이렇게 전방탐색 구문 사용해도 됨
- 정답이 되는 여러가지 방법이 있음
메소드를 포함한 URI 영역만 검사하려면?
- get \S+ : S는 빈칸이 아닌것만 검사하므로 다음 빈칸 전까지만 검색돼 URI 영역만 나옴
- get[^ ]+ : 이것도 빈칸이 아닌 문자가 하나이상온다는 의미
- get[^?]+\?\S+ : URL과 변수값까지 찾고 그 뒤에 문자가 아닌 데까지 찾기
URI 영역만 검사하려면?
- \/\S+[^>?]+\?\S+
- \/\S+(?=http)

URL 영역만 검사하려면?
- \/[^?]+\?
변수 영역만 검사하려면?
- (?<=\?).+(?= http)
- [^=?&\n]=[^=&\n]+&[^=&\n]+=\S+

Referer 영역만 검사하려면? URL만 검사하려면?
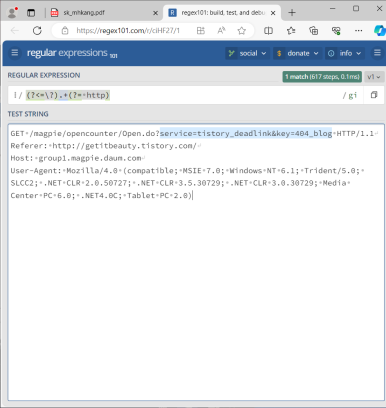
- (?<=referer: ).*
- http 안에 내용만 : (?<=referer: http:\/\/).+com
- 'http://'로 시작, 'com'으로 끝나는 URL을 검사하려면?
- (?<=: )http.*.?com
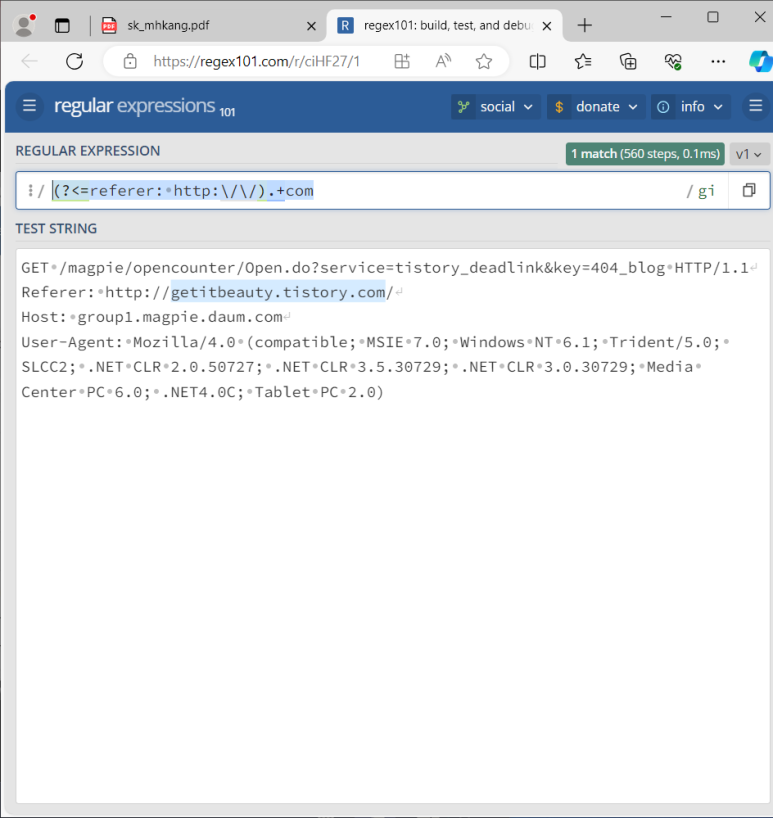
User-Agent 영역만 검사하려면?
- user-agent:.*(?= \S+: )
- user-agent:.? \S+\)

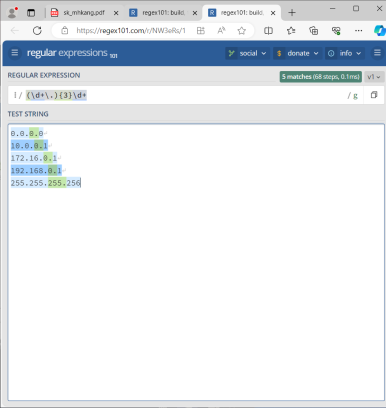
IP 주소를 검사하려면?
- (\d+\.){3}\d+
- [0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5]
- ((1[0-9][0-9]|2[0-5][0-5]|[1-9][0-9]|[0-9])\.){3}(1[0-9][0-9]|2[0-5][0-5]|[1-9][0-9]|[0-9])\b

VIM 정규표현식
VIM 정규표현식
- VIM은 텍스트 우선, PCRE는 정규표현식 우선
- 매직모드 (\v)를 이용하면 PCRE와 유사한 정규표현식 사용 가능
- 가변적 문자열 범위를 검사하는 메타문자
- 문자열 범위 지정 가능

- 검사 위치를 지정해주는 메타 문자

- VIM에서의 경계 문자 차이
- PCRE에서는 \w(알파벳 소문자 대문자)
--> \b : 나랑 성질이 다른 것을 경계로 잡아줌 \B는 같은 것 경계문자로 잡아줌
--> \b 같은 것만 있음
솔직히 이 부분 뭔 지 이해 안됨
- 수량을 결정하는 메타문자, 수량자(Quantifier)
- 최대 검사 모드

- 최소 검사 모드

- 동작 방식을 수정하는 메타문자, 수정자(Modifier)

Why VIM?
- 강력한 성능
- 데이터 구조 파악 및 변환을 지원하는 다양한 기능이 있음

sshd 지우기

지워짐!
VIM 심화
- 치환 명령어 작업 순서 : 치환을 원하는 문자열 검사 > 검사 성공 > 치환 명령어 작성 및 실행
- :%s/치환전 문자열/치환후 문자열/
- 마지막 검색어 기억해줌
- 치환작업 편리
- 원본을 유지하며 구분자를 추가하고 싶다면?
- /\v^.{15} -> %s//&ㅋ /
룰 최적화
패턴기반 룰
SQL Injection 탐지 룰
- 퍼센트 인코딩

%20and%20
+and+
- 이렇게 웹 사이트마다 빈 칸을 의미하는 것이 다름
- SQL Injection으로 로그인 성공하기


- 이 취약점을 %20 룰을 추가해서 막아보자
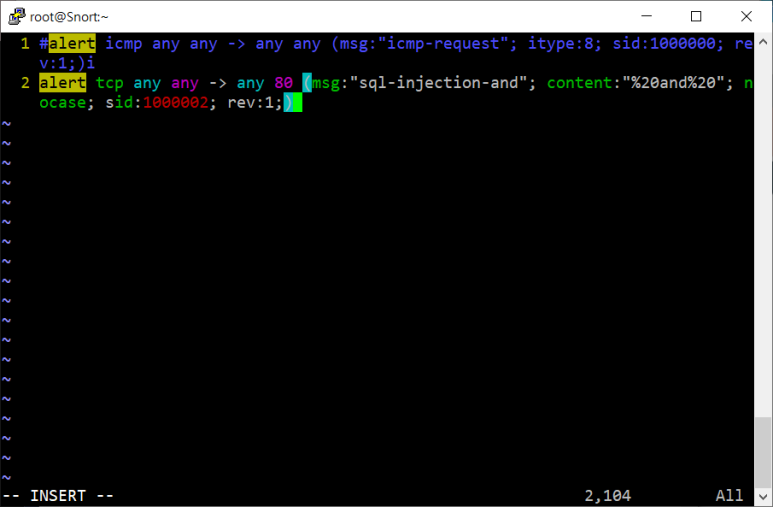
룰 추가 해주고
연동해주고
*참고사항*
cmd로 접근하고 싶은 파일로 들어가서 탐색기 cmd 작성하면 그 경로에서 실행 된 걸로 됨!

업로드 된 파일 지우기는 rm -f sqli.pcap
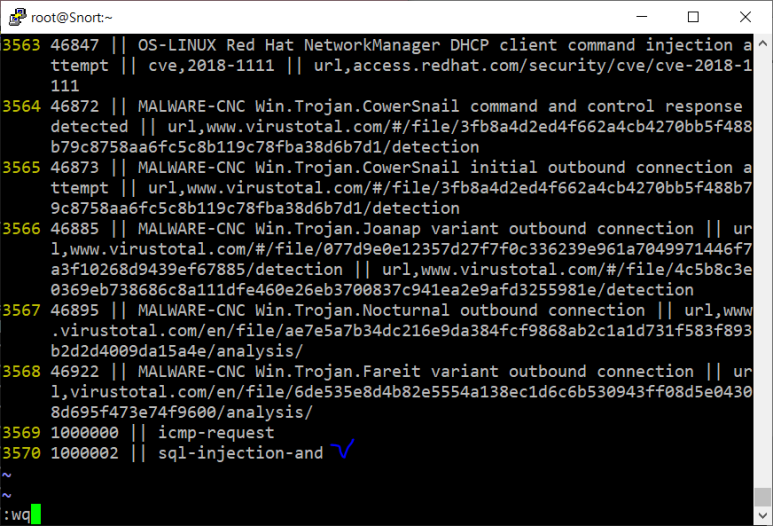
- 이제 파일 검사 실습 (sql-injection-rule이 잘 들어갔나 확인하기)
- 이제 탐지 데이터들을 조회해보자

- VIM에서 해당 로그 확인해보기

- URL만 필요한데 HTTP 트래픽 데이터이다보니 불필요한 정보들이 너무 많음
- 없애기 위해 데이터를 한 줄로 가져와보자

- 이제 http 뒤쪽은 없애주자!
--> / http\/.* 검색하고 : %s///
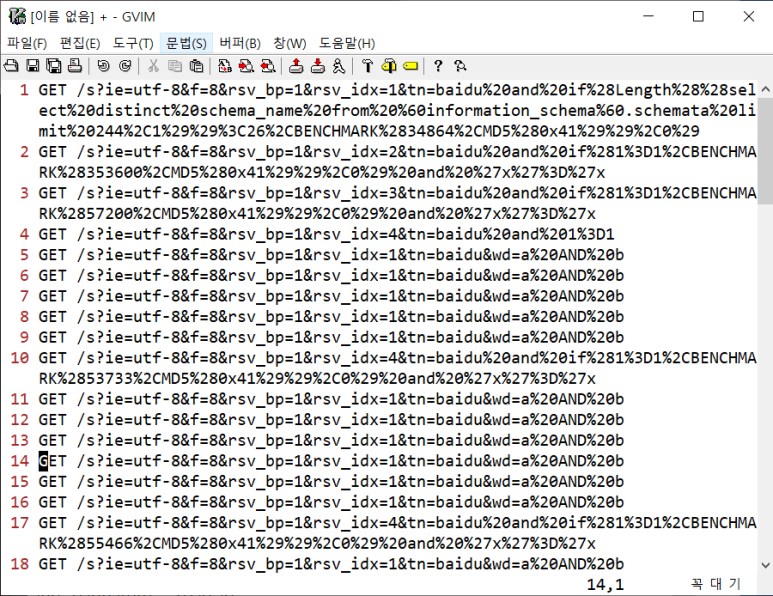
- 이제 공격인 지 아닌지 확인하기 위해 %20and%20을 기준으로 확인해봐야 한다
- %20and%20 찾기
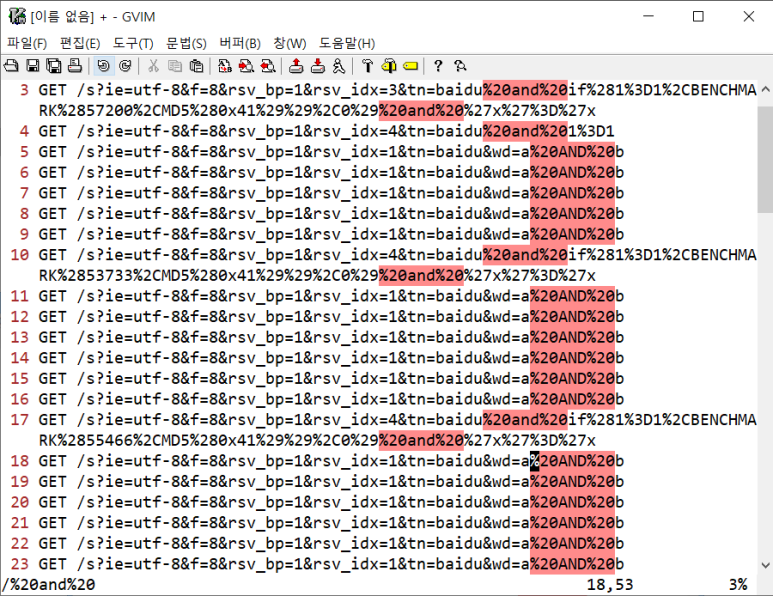
- 탐지패턴을 기준으로 필드를 쪼개서 공격여부 확인표를 만들거기 때문에 좌우구분을 위한 치환 명령 사용하기
- :%s//ㅋ&ㅋ/
--> 구분기호는 다른 문자와 중복되면 안됨 (일관되지 않는 테이블 구조가 나오기 때문에)

보면 양 옆에 ㅋ 붙어있음
- 엑셀에서 전체 데이터 복붙해 오고 구분기호 ㅋ을 기준으로 나누기
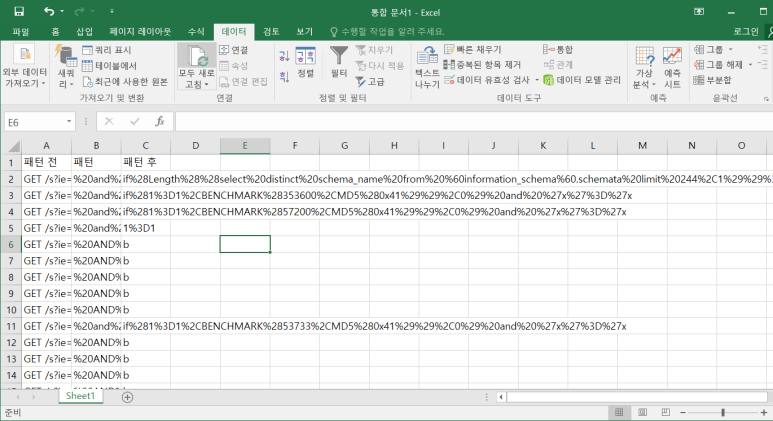
- 제목에 필터 축하해서 패턴 후를 보면 b를 제외하고 전부 공격임
- 3D는 equal임 그래서 1=1 해본 것이라고 알 수 있음
- URL 디코딩
- 자주사용되는 인코딩 패턴

- 활용해서 디코딩을 해보자

- 현재 정확도가 10%도 안되므로 정확도를 올려보자
- ㅋ넣기 전으로 돌린 후 https://regex101.com/ 가서 복붙
- %20and%20(\d%3d\d|if%28) 해보니까 7개 나옴
--> 이거를 기존 룰에 추가해봅시다
- 룰 정보 수정 후 signature 테이블과 event 테이블 초기화 후 barnyard와 snort 다시 실해보니 7개 검색 됨

--> 룰 정확도가 100%가 됨
- wireshark에서 똑같이 테스트 해볼 수 있음

- spli2.log 파일을 보면 +and+로 탐지중임
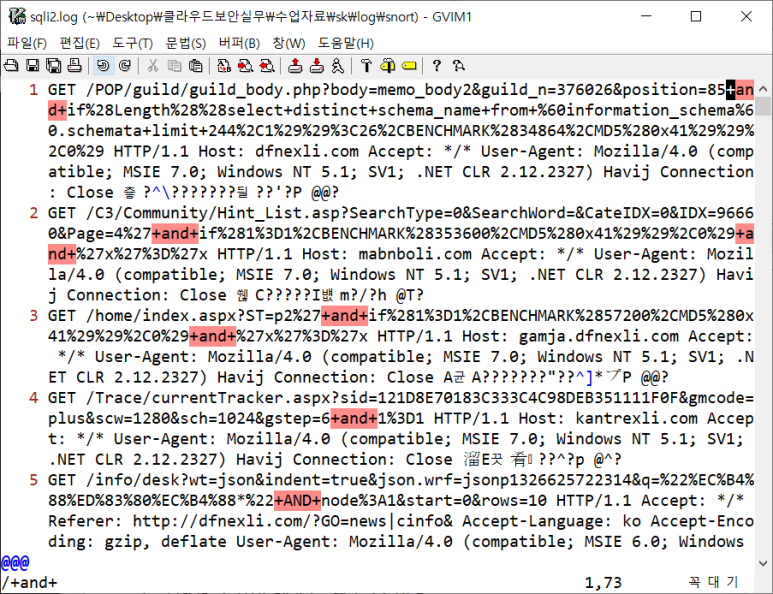
- 똑같이 http 뒷부분을 지우고 +and+ 기준으로 필드 분류를 진행할 것임
- 만약 :%s//ㅋ&ㅋ/g 하면 한 줄에 여러 +AND+ 인식하므로 뒤에 g는 빼고 하면 맨 앞 +and+만 적용 됨
- 엑셀로 가져와서 확인해 보니 2000개 중 14개만 공격으로 판정!
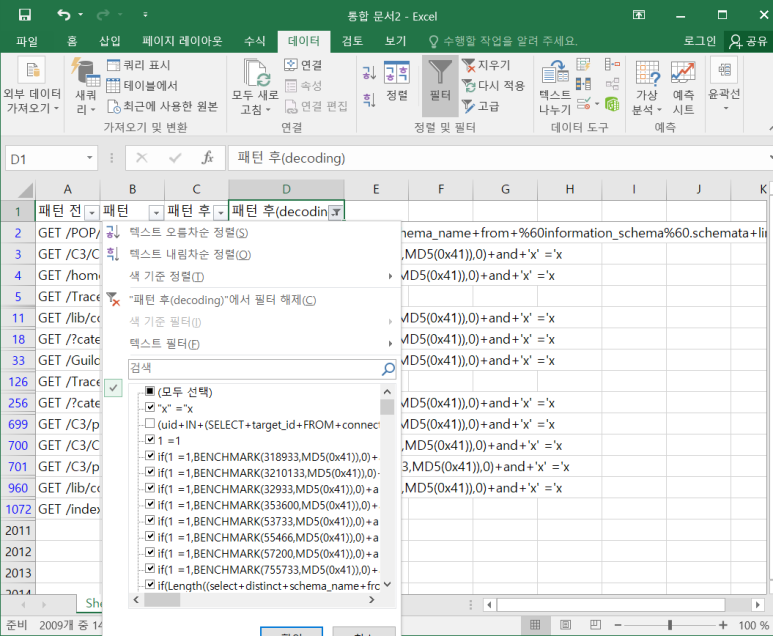
공격인 것만 보이게 설정

hack 라벨 붙임
- 화이트리스트 방식으로 룰 만들기를 해보자
ASP웹쉘
- asp_webshell.log 열어보기
- 마찬가지로 http 쭉 없애보기

- :g\?action=\d 하면 1300개 남음 이상함
- ASP 파일이 들어있는 로그와 URI를 검사하고싶은데 남은 것들이 이상함
- 룰에 문제가 있음을 짐작 가능
- /\.asp?action 검사해보기 그리고 :v//d 하고 /\v[^/]+\.asp\?action\=\S+ 해서 이거 포함된 데이터들만 남기기
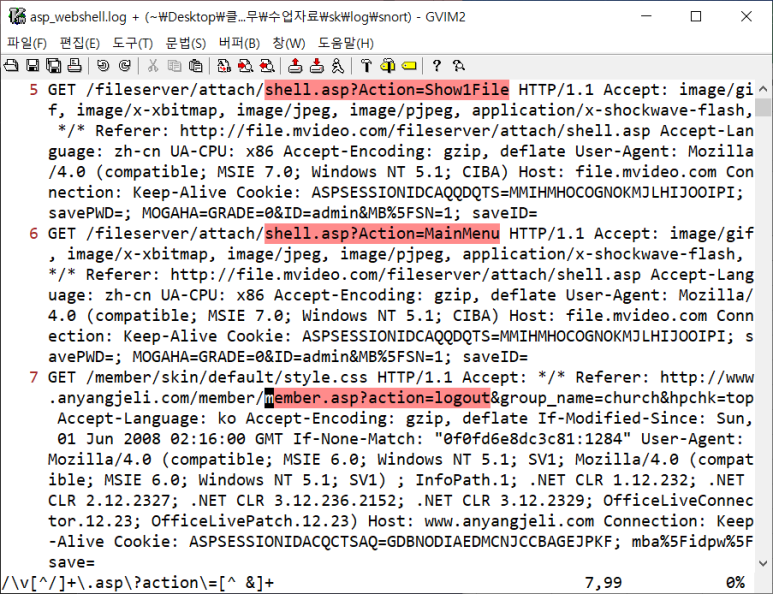
- 추가로 뒤에 이어져 있는 데이터에 대해 알기 싫기 때문에 /\v[^/]+\.asp\?action\=[^ &]+
- 마찬가지로 엑셀로 옮겨서 보는데 우리는 구분기호 안에 있는 정보만 필요함!

- 사진보면 ? 전까지 URL정보고 마지막에 파일 정보가 나오는 것
- 우리가 필요한 정보만 남겨봅시다

- 이거를 피벗테이블로 봐보자
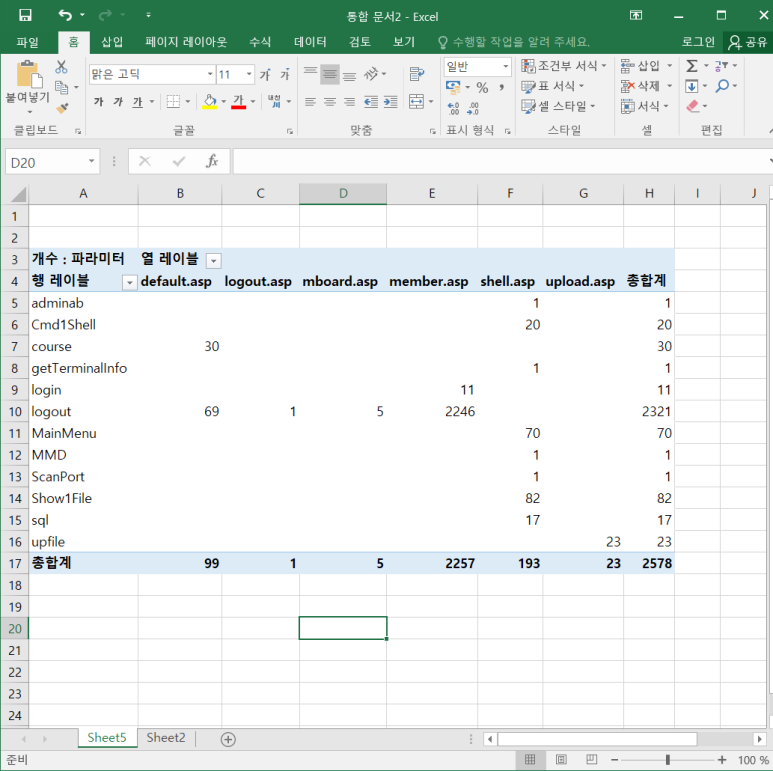
- shell.asp 보니까 다른 파일들에 비해 다양한 변수값을 사용하고 있음
--> 의심됨
--> 확인 결과 중국 사이트에서 접속한 것 알 수 있었음
- 룰 수정
룰을 만드는 두 가지 방법
- 블랙리스트 : 위험해보이는 문자열 찾기
- 장점 : 알려진 공격은 확실히 방어
- 단점 : 알려지지 않은 공격 방어 불가
- 화이트리스트 : 위험하지 않은 문자열 회피
- 장점 : 알려지지 않은 공격 방어 가능
- 단점 : 정상 패턴 정의 어렵
*패턴 매칭은 완벽하지 않음! 패턴 일치한다고 전부 공격이라고 볼 수 없기 때문
임계치기반 룰
발생량 기반 룰
- DB에 저장해서 SQL로 분석할 예정
- TestDB에 테이블 구축
- ips table에서 import data from CSV
- 필드 구분 디폴트 값이 \t : tab 문자를 의미함

- 우리가 가져오는 파일은 쉼표로 되어있어서 수정해줘야 함
- 데이터 살펴보기
- 룰별로 개수 세보기

- fingerprint의 sip개수와 dip개수 확인해보기
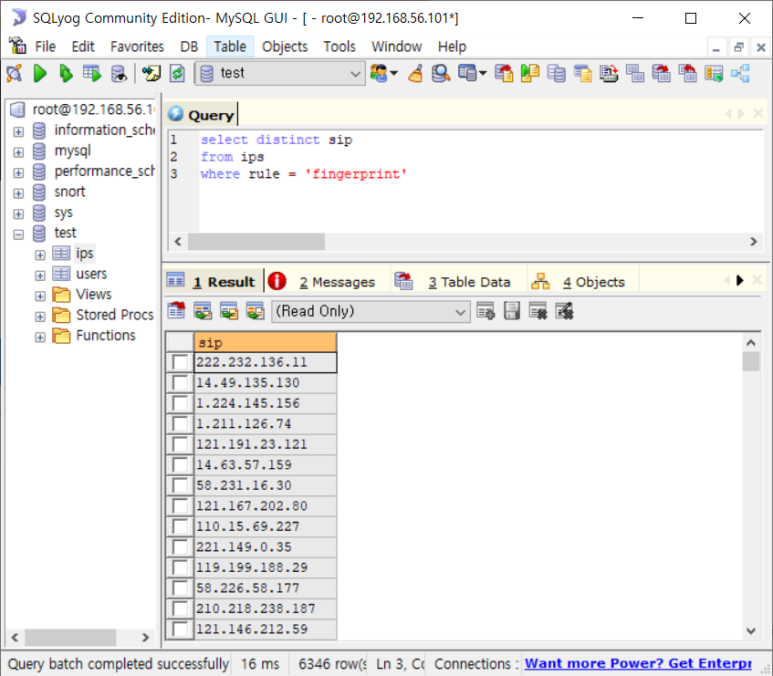
- sip 개수 6346

- dip개수 10개
- 출발지 IP개수와 목적지 IP개수를 비교해봄으로써 알 수 있는 것은?
- 누가 클라이언트고 누가 서버인지!
--> 많은 쪽은 클라이언트로 판단!
- UDP packet flooding으로 port 개수 봐보자
- 보통 DDoS 유형의 공격들이라 가장 많은 로그들
- IDS/IPS에서 막기 힘듬 그래서 별도의 DDoS 막는 장치사용하는 것

- udp packet flooding의 sip
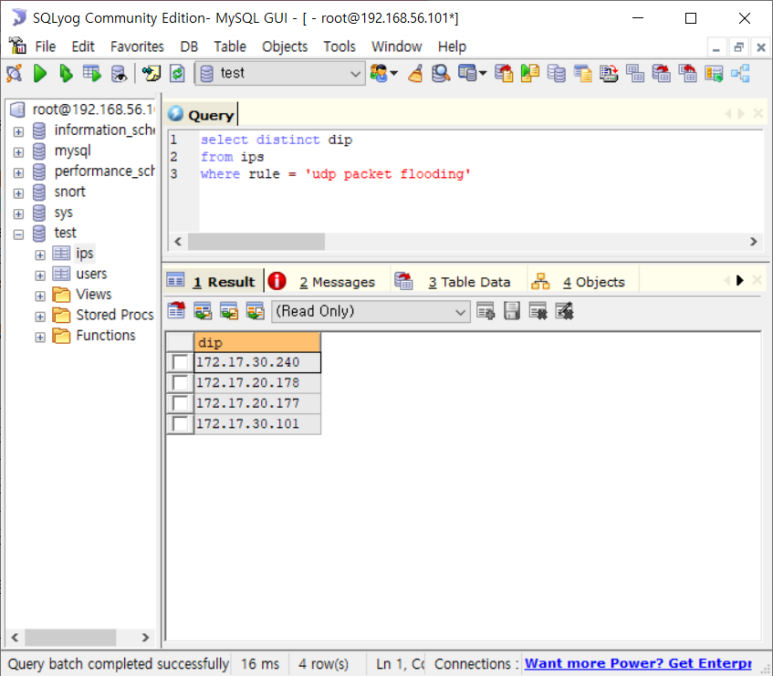
- dip
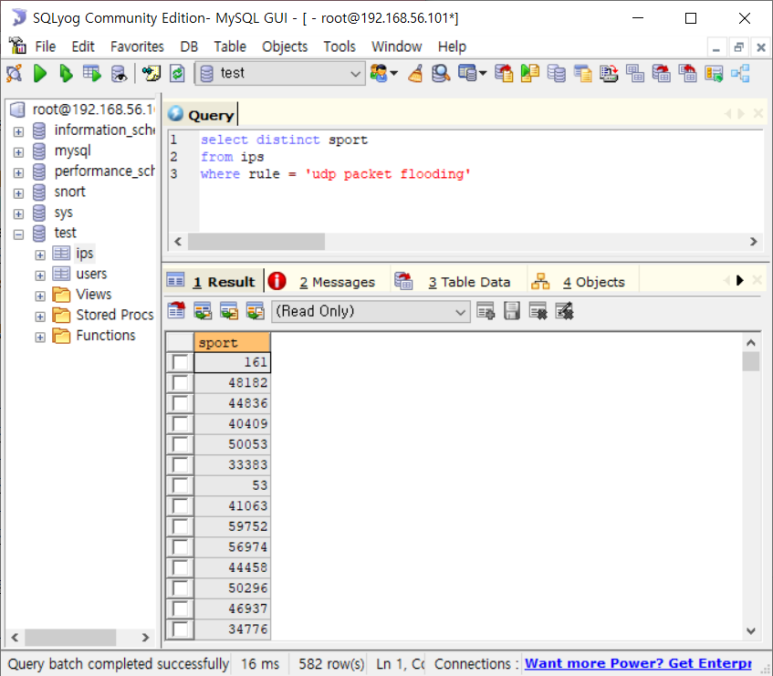
- sport 개수 582개

- dport 79개
- 위에서 알 수 있는 것은 port 개수가 크게 차이가 나지 않는다는 것!
- 뚜렷하게 누가 클라이언트고 누가 서버인 지 알 수 없음
- 그럴 때 출발/목적지간 현황 분석!
- sip, dip, sport, dport 동시분석하는 것!
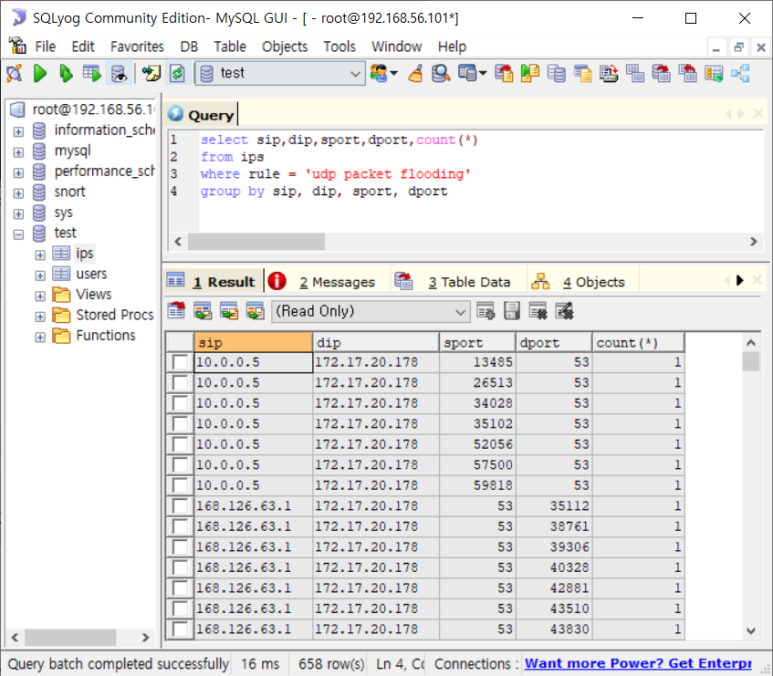
--> 4개 조건이 같으면 합치고 다르면 따로 세는 것
--> 658개가 되었으므로 줄기는 함
- 포트 정보 축약하면 더 도움이 될 것으로 판단!
- 1024번 이상이면 client port일 가능성이 높다는 것을 이용

- 161 port: SNMP 네트워크 장비가 성능 측정할 때 사용됨 (제외 필요)
- 따라서 맨 위의 두 ip와 출발지 port는 udp packet flooding으로 탐지하지 않겠다는 것
--> 만 개 이상의 로그를 안잡을 수 있게 됨
- 세 번째것도 마찬가지이므로 기업 내부에서 SNMP를 쓰는 지 확인 후
--> 공격으로 탐지 안하겠다는 것을 합의하면 다량의 로그들을 줄일 수 있는 것
- 이를 보며 대량으로 발생하지만 sql로 분석해보면 공격이 아닌 것을 알 수 있기도 함
- 임계치 기반 분석은 패턴 분석과 다르게 다각도의 분석이 필요함 우리가 실습해 본 것은 간단하게 끝난 사례임
* 훨씬 많이 운용되는 룰은 패턴 분석 기반이지만 가장 많은 로그가 발생하는 것은 임계치 기반 룰임 udp는 일반적으로 탐지하니까
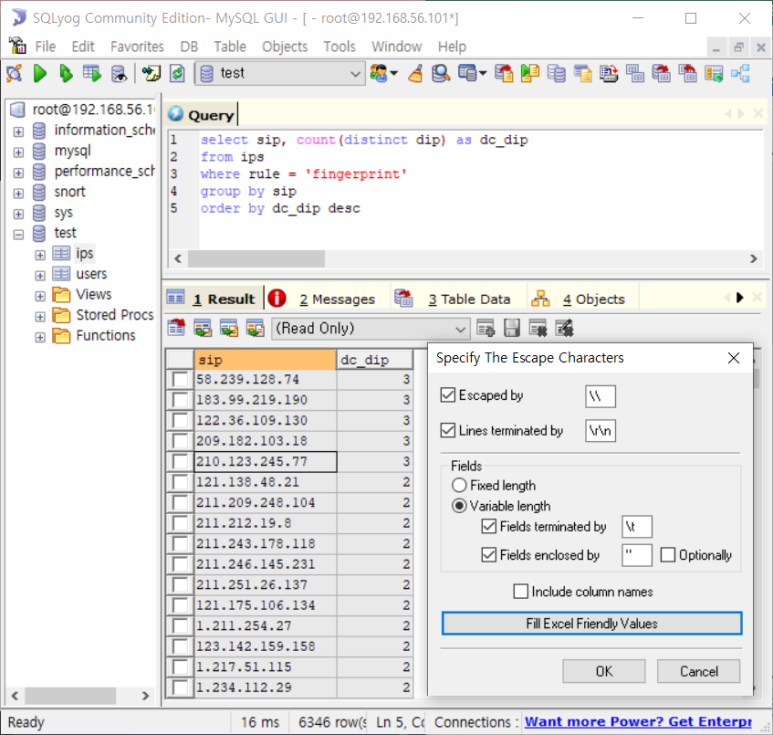
- 다음으로 발생량 많은 fingerprint도 distinct를 활용해 출발지와 목적지와의 관계를 분석해보자
- 출발지 별로 목적지의 고유 개수를 세겠다는 것
--> copy해서 정리해둘 필요 있음
- 고유개수 측정 정리한 것(IP와 Port)
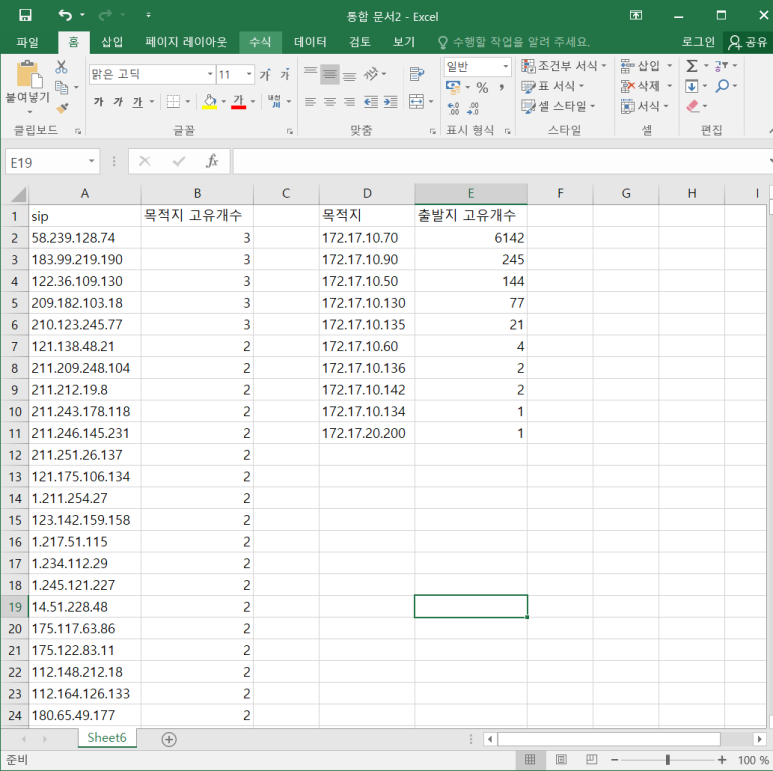
- IP
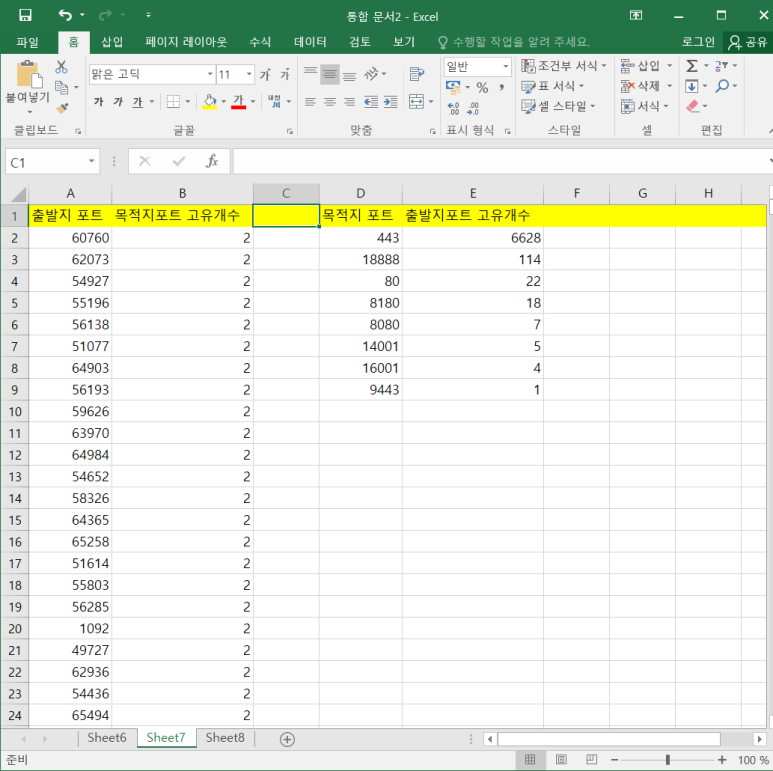
- Port
--> 정리한 것을 보니 172.17.10.70이 443포트를 사용하고 있다는 것을 알 수 있음 (요기가 서버다!)
--> 그래서 이 IP와 포트는 예외처리를 하는 등 룰 최적화를 위한 판단에 도움이 됨
- ack storm 분석
- 얘는 사실 sip, dip, sport, dport 한번에 봤을 때 구십 몇개였어서 한번에 분석할 수도 있긴하지만 따로보면

- tcp invalid flags (maerong) 분석
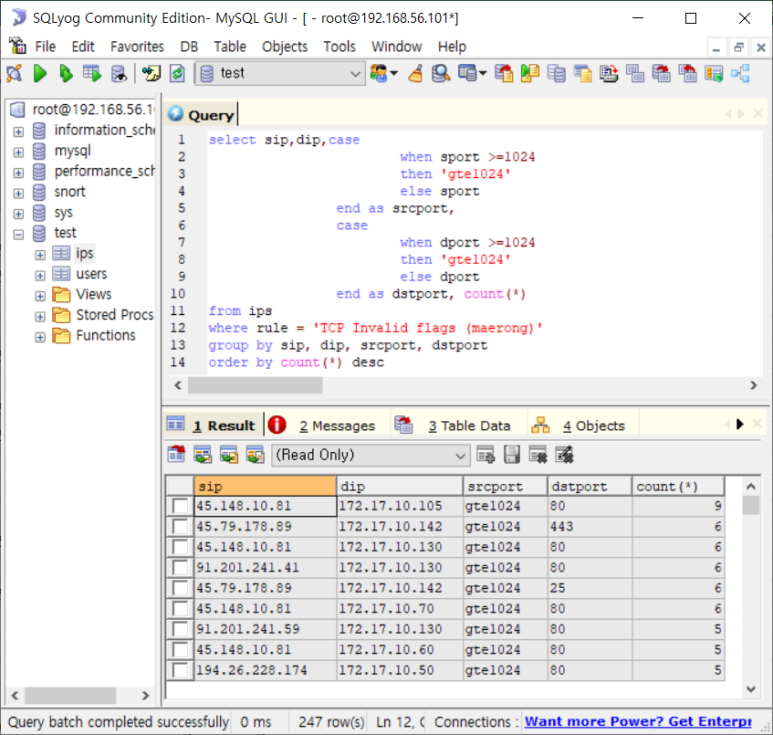
- 이렇게 한번에 볼라니까 247개라 분석하기 힘드니까 IP따로, Port 따로 쪼개서 보기

이상징후 분석
통계분석
- 어떤 현상을 종합적으로 한 눈에 알아보기 쉽게 일정한 체계에 따라 숫자로 나타낸 것을 통계라고 함
- 인구조사 : 가장 오래된 통계
- 좀 더 세분화된 데이터 필요성
- 성별 인구조사 -> 연령별 인구조사
- 특정 : 상태를 세분화할수록 더 잘 알게 된다
- 상태(필드)가 분리된 데이터베이스
- 필드, 레코드, 테이블
데이터베이스 구조
- 필드 : 동일 성격의 데이터 집합
- 하나의 필드 제작 시 반드시 같은 성격의 데이터만 들어가야 함
- 레코드 : 여러 필드로 구성된 데이터 집합
- 테이블 : 필드와 레코드의 집합
데이터 분석
- 데이터 계산
- 데이터 전처리가 데이터 분석의 80%
- SQL : 데이터 계산 언어
- 제일 중요한 조건 : 정확한 데이터
- 보안 분야에서도 정확한 데이터의 숫자를 세어야 한다
무의미한 통계
- 전통적 보안 관제 분야
- 핵심 네트워크 보안 로그 (IDS, IPS 등)
- 필터링 (패턴 매칭)된 기록
- 룰 정학도 개선을 통해 오탐 문제 해결
유의미한 통계
- 보안관제 소외 분야
- 방화벽, 서버로그 (os 웹, DNS등)
- 사실 관계를 그대로 기록
- 통게 분석을 통해 미탐 문제 해결
스플렁크
이기종 데이터 분석 플랫폼
- 다양한 로컬 / 원격 데이터 연동 지원

인덱서
- 데이터 저장(인덱싱)
- 포워더/ 검색헤드/ 마스터 기능 포함 (헤비 포워더)

포워더
- 데이터 수집 / 가공 / 전공
분산 데이터베이스 환경 지원
- 단독 / 클러스터 운영 지원
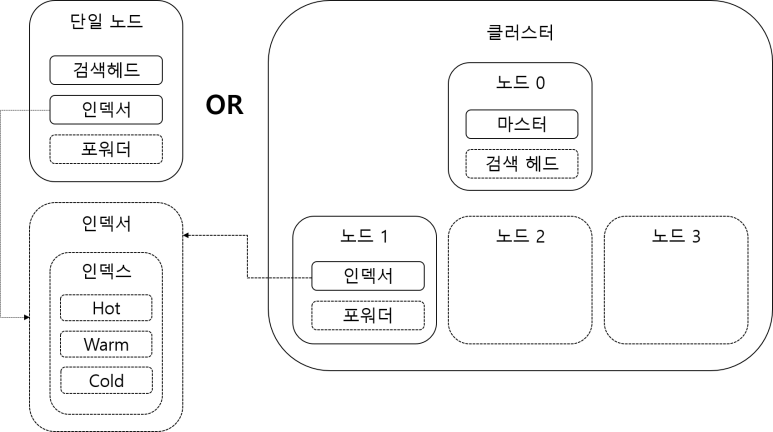
인덱스
- 데이터 단위 저장(DB 테이블 역할)
- HOT / Warm / Cold 버킷 단위 갖고 있음

스플렁크 주요 메뉴
- 앱 > Search&Reporting

- 컴퓨터 관리에서 스플렁크 시작 수동으로 바꿔주기
- 설정 > 데이터 추가
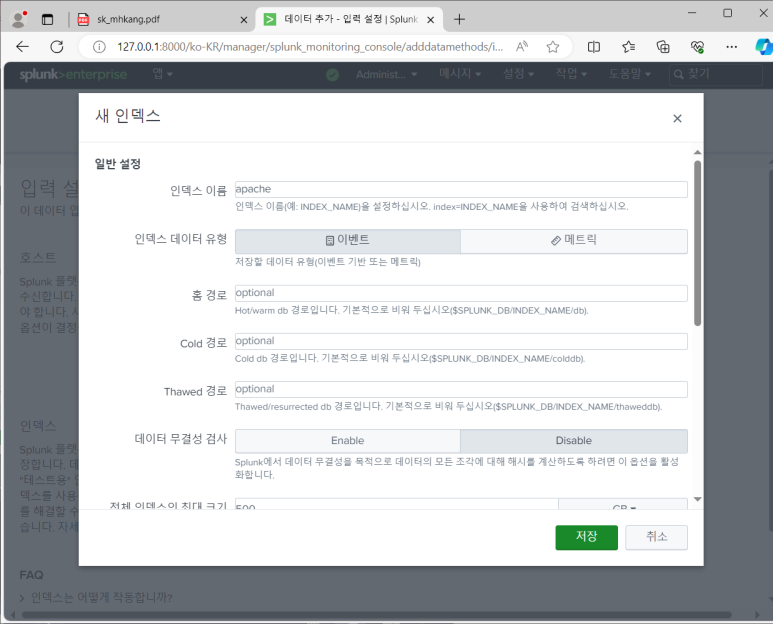
- 파일 업로드 메뉴 : 1회성
- 파일 선택 > 원본설정 apache.log

- Source Type 설정
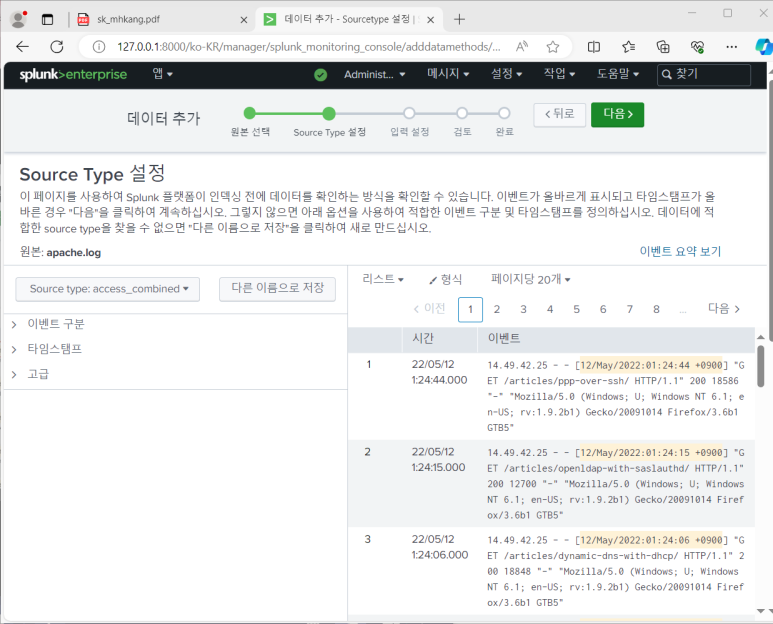
--> 데이터 소스의 유형별로 전처리 과정 만들어둠
--> source type : access_combined로 자동 지정되어 있는 것을 볼 수 있음
- 입력설정 : 기본값은 main임

--> 새 인덱스 만들기 (Thawed 경로 :삭제 되는 것)
- 검토
- 제출
- 검색 시작
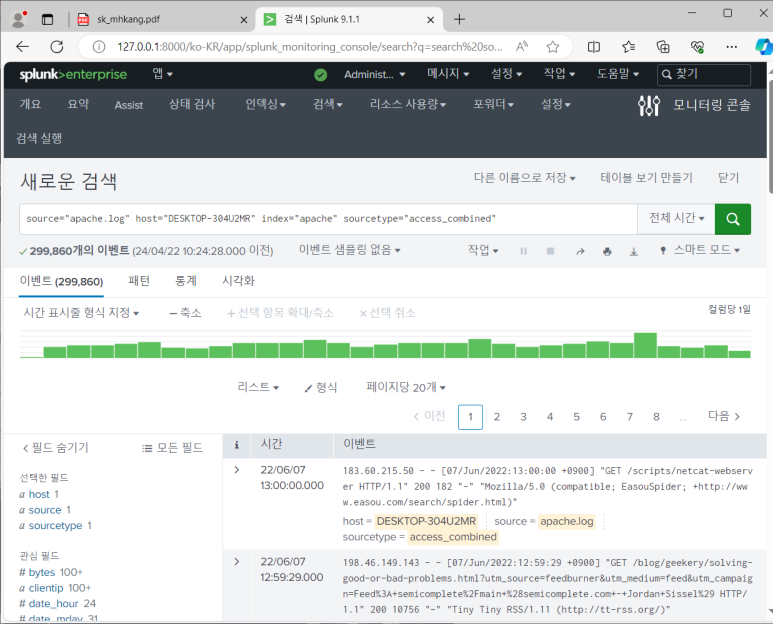
- 4개의 검색 명령어 사용됨
--> 쓰인 검색어 중 index가 가장 중요함! index = "apache"만 하면 똑같이 전부 나오게 됨
- 299,860개의 데이터가 검색됐는데 실제 로그 파일의 데이터 개수와 같은 것을 알 수 있음
- 유형 변경해서 보고 싶은 데이터만 선택해서 볼 수 있음
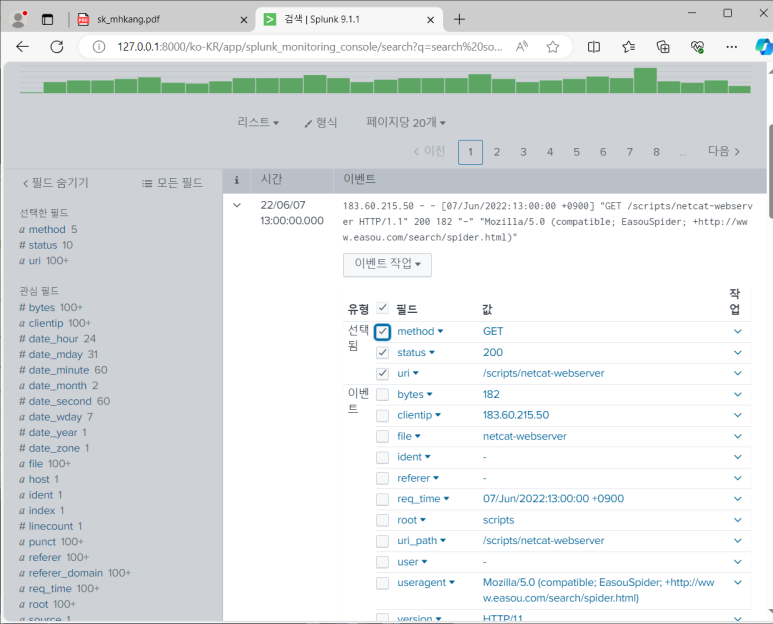
변경
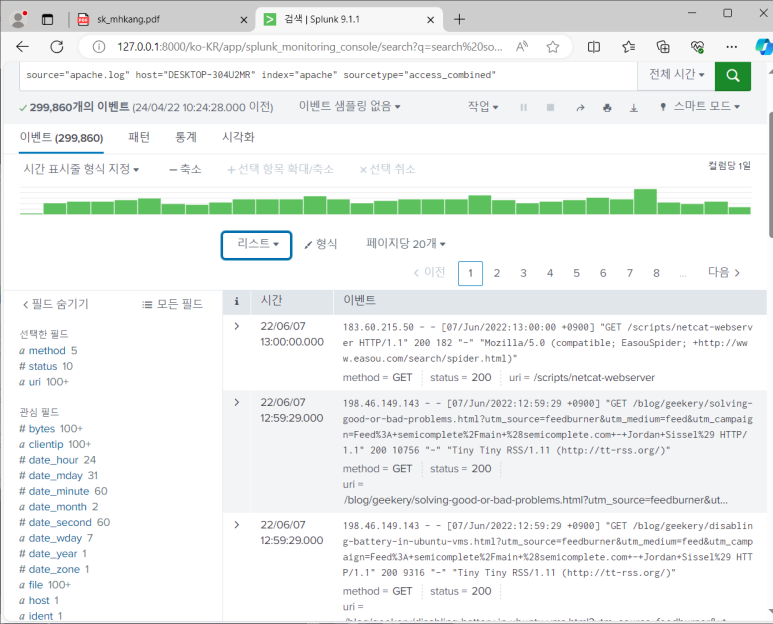
결과
SPL(Search Process Language)
- 스플렁크 언어
- UNIX + SQL 컨셉
- 내가 스스로 어떤 필드에 어떤 정보가 들어있는 지 알아야 잘 활용할 수 있음
- 검색 (search)
- 최초 입력되는 구문은 (search 명령 없이) search로 인식 됨
- 필드 = "값" 구조의 검색어를 AND, OR, NOT, IN 등의 연산자와 함께 사용
- 필드를 지정하지 않으면 전체 원본 데이터가 저장된 _raw 필드 자동 지정
- 연산자를 지정하지 않으면 AND 연산자 자동 지정
- 필드와 연산자는 대소문자를 구분, 검색어는 구분하지 않음
- 와일드카드(*) 사용 가능
- 예시


- 관리자 > 기본설정 > SPL 편집기 > 검색 형식 자동 지정
- 이렇게 하면 편리하게 검색 작성 가능

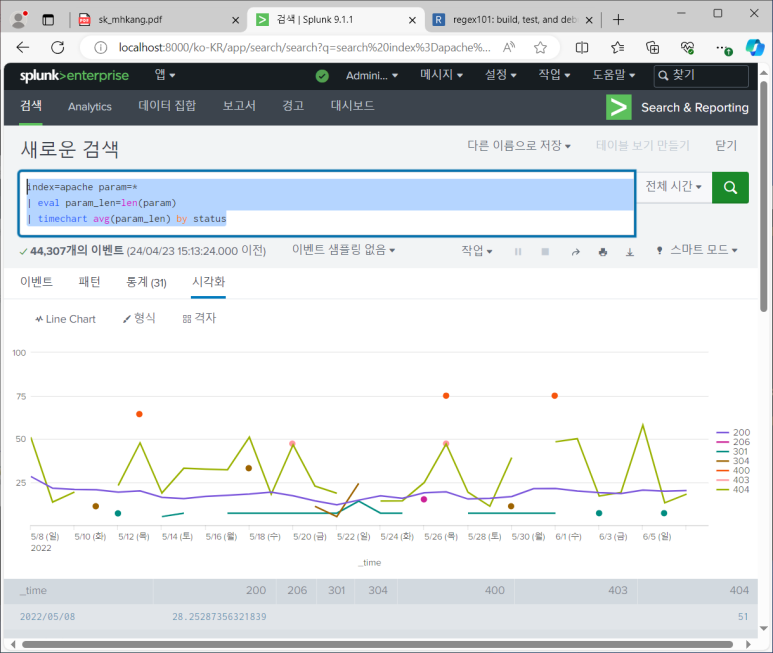
- 가공 (eval 명령어)
splunk.com > resource > documentation > Splunk Enterprise > search and report > Search manual(동작 방식 및 원리 설명), Search Reference (검색 명령어 관련) 그래서 Search Reference
- splunk에서 사용 가능한 명령어 리스트 볼 수 있음
- docs.splunk.com 가면 바로 명령어 관련 페이지로 가짐
- 여기서 eval func 볼 수 있음
- 문자열/숫자 연산 및 replace, split 등 다양한 함수 기능 지원
- 예시
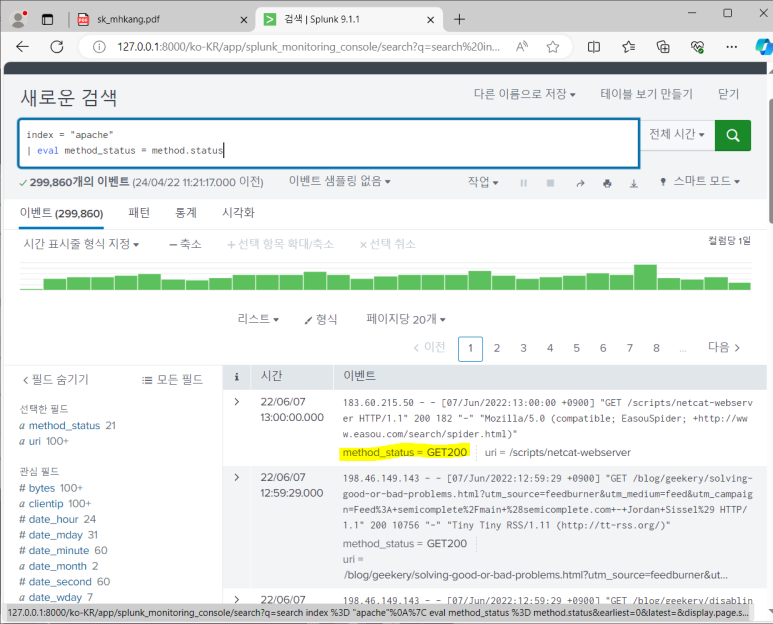
- 항상 검색 하며 보기 힘드니까 설정해주기
- 설정 > 필드 > 필드 별칭 - 새 필드 별칭

- 계산된 필드

- 통계 (stats, chart, timechart)

stats
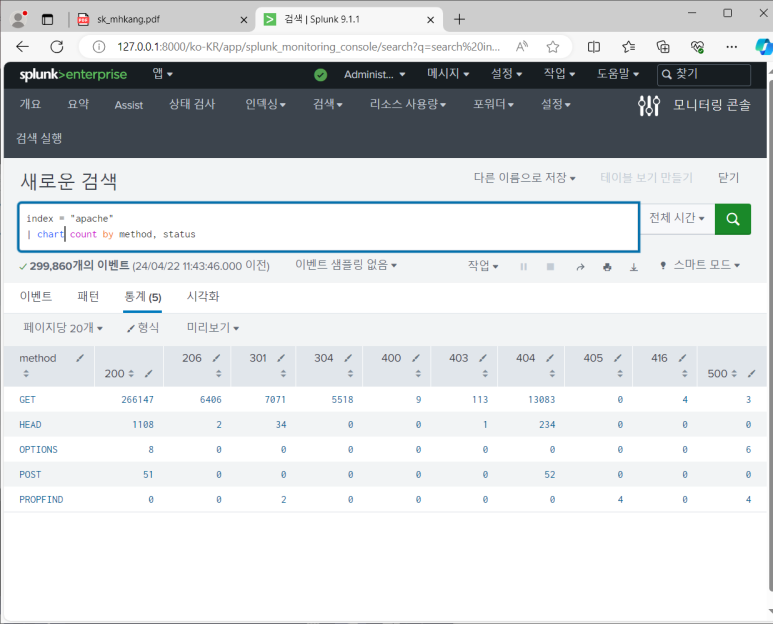
chart
--> 시각화
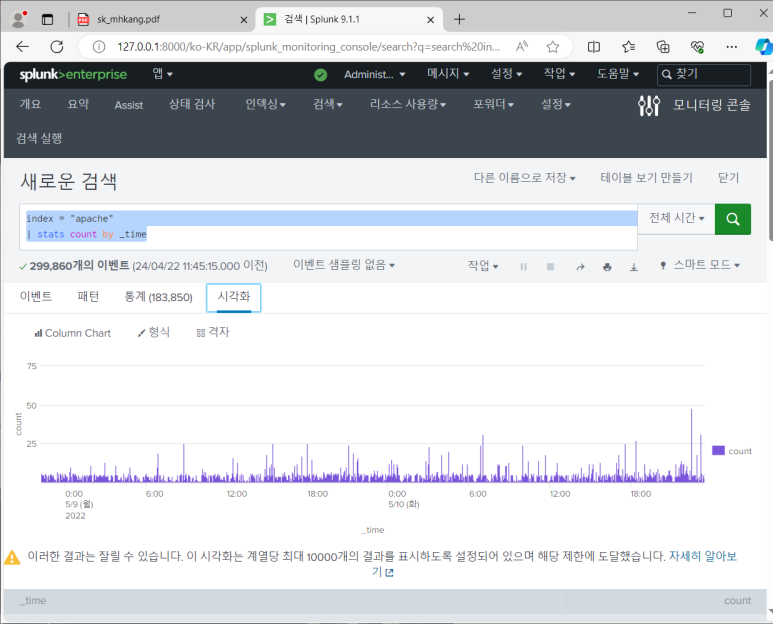
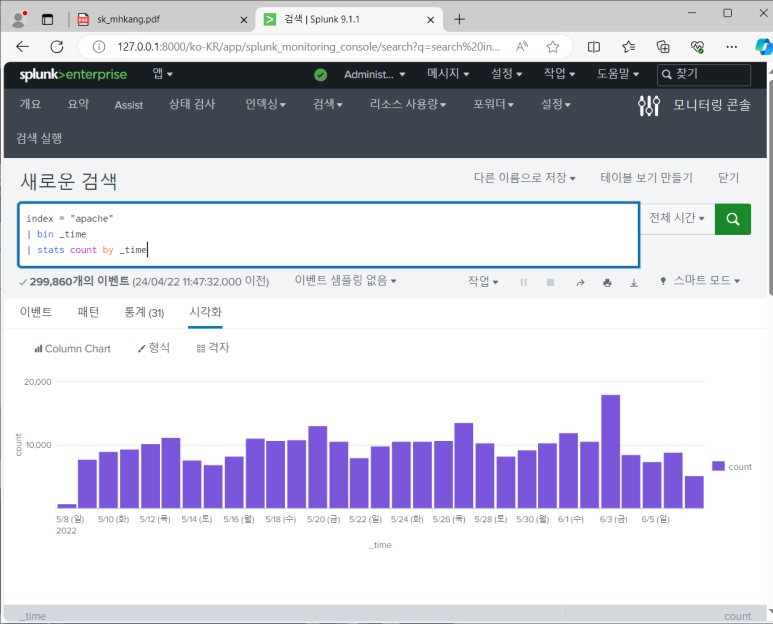

--> chart 스타일과 형식 바꿀 수 있음
--> 시계열 차트를 그리고 싶으면 stats말고 chart를 써야 한다는 것!
모니터
- 기본 아파치 인덱스 삭제 후 다시 데이터 추가 > 모니터
- 원본선택 : 파일 및 디렉터리 > apache-sample2.log > 소스 타입 : 자동설정 > 입력 설정 : 새 인덱스 apache> 검토 > 제출
- 참고사항 : 웹에서 설정한 것들이 설정 파일에 기록 됨
C:\Splunk\etc\apps\search\local\input.conf에 다 기록된 것 확인 함
인덱스 만들었던 것 삭제 하며 확인해보기
데이터 연동
- 설정 > 데이터 입력 > 파일 및 디렉터리
- 실시간 모니터 / 포워더의 연동 데이터 지정 (forwarder에서 설정)
- 포워더의 데이터 수신 서버 지정 (forwarder에서 설정)

- 데이터 수신 서버의 수신 포트 지정 (indexer에서 설정)
- 포워드에서 보내기러 한 포트와 인덱스에서 받기러 한 포트 번호가 같아야 데이터가 잘 들어오겠죠?
- 인덱서는 포워더 기능도 있기 때문에 인덱스 끼리도 데이터를 주고받을 수 있음
- 웹 UI 설정으로 데이터 받아보기
--> 인덱스에서 새 인덱스 만들기 apache
--> 전달 및 수신 > 데이터 수신 > 새로 추가 > 9997
--> 인덱스에서 전달 받을 준비 끝난 것
--> 포워더에서 데이터를 다시 받기 위해 아까 이미 받아둔 정보를 지워보자
--> 다시 데이터 받아오기 (아까 받을 때와 같은 절차임 forward 부분)
--> 해시값을 기억하고 있기 때문에 이렇게 지우고 다시 넣어줘도 안됨
--> 추가 설정 : inputs.conf에 crcSalt = abc 추가 (해시값 재계산식)
--> splunk restart
--> 다시 수집되는 것 확인 가능
--> splunk stop으로 마무리
- 정리하자면 파일 업로드는 마지막으로 읽은 데이터의 해시값을 저장하지 않기 때문에 중복해서 데이터를 올릴 수 있지만 모니터는 해시값을 저장하기 때문에 해시값을 바꿔줘야 지웠다가 다시 올릴 수 있다는 것
- 데이터 분석하기 위해 데이터에 대해 알아 볼 필요가 있음
- apache-sample2 를 엑셀로 열어 불필요 행 지우고 날짜 바꿔주기
- 바꾼 것 엑셀에 바궈 넣어주면 시간 값으로 인식하는 것을 볼 수 있음
--> 이후 yyyy-mm-dd hh:mm:ss 이렇게 셀 형식 바꿔주면 원하는 대로 됨

- 피벗 테이블 만들어서 확인해 보니 splunk와 동일 함
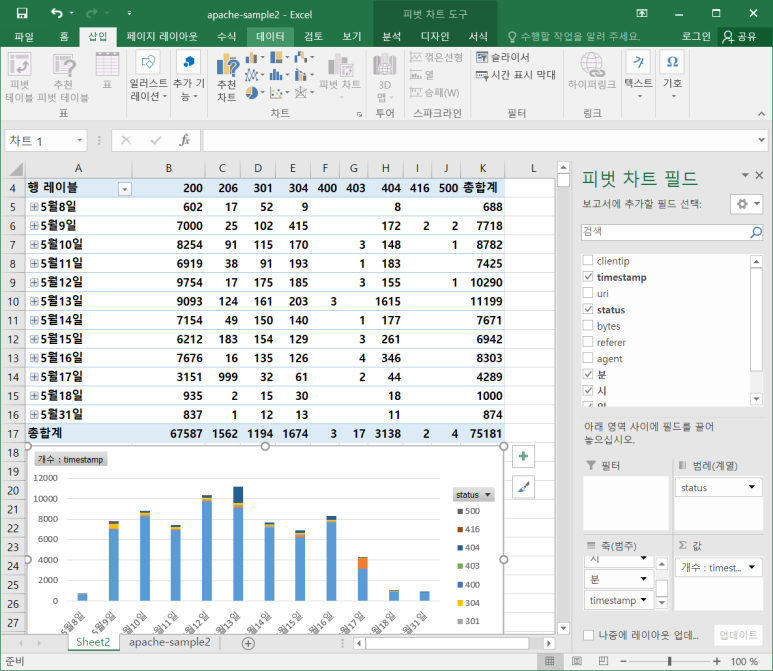
- uri 부분도 변경해 준 후 같은 방식으로 피벗 테이블을 만들어 여러 데이터를 확인해 보면 좋음
- 이 작업을 splunk에서도 할 수 있으므로 편한 곳에서 하면 됨
Splunk DB Connect
- 앱 관리 > 파일에서 앱 설치 > splunk-db-connect 선택 후 추가
- Splunk DB Connect 앱 > 설정 > JRE installation Path - jdk-11.02 경로 입력 > 재시작

- mysql connector 드라이버 설치
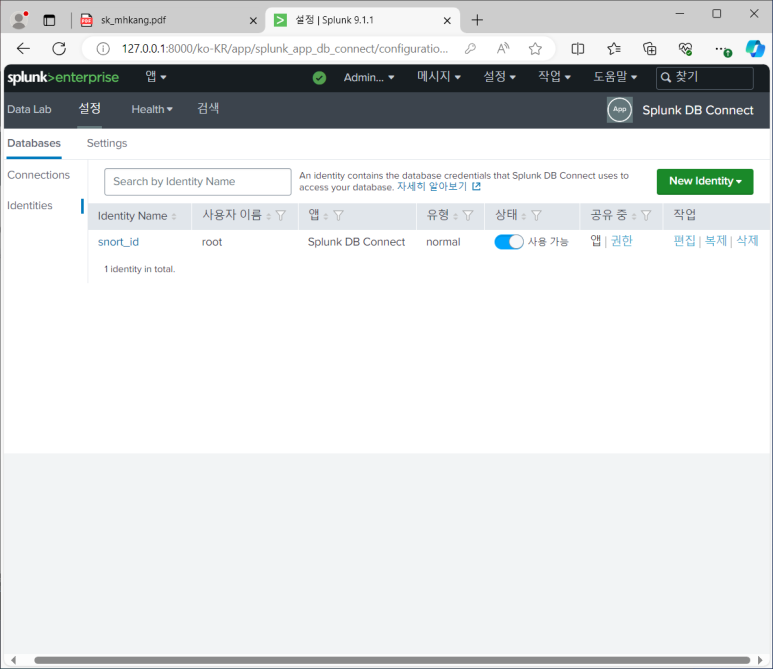
- DB 계정 정보 등록
- 설정 > Identity > New Identity

정책 이름 설정
이름 확인
- DB 연결 정보 등록
- connection > new connection

연결 정책 이름 설정
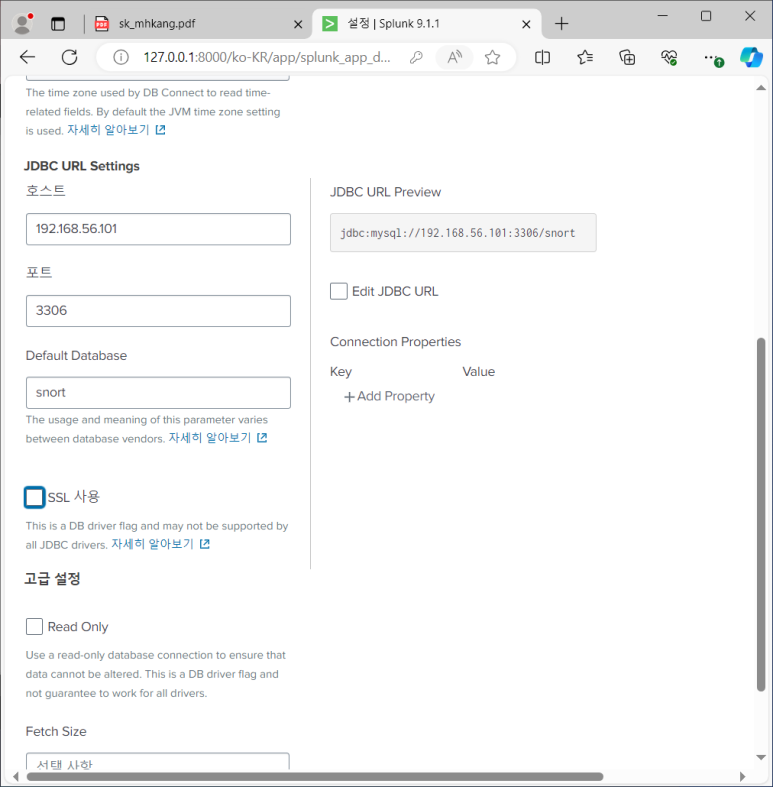
서버 정보 입력

결과 확인
--> 리눅스 실행해야 결과 저장됨!
- DB 연동 설정
- Data Lab > Inputs > New Input
--> connection : snort_con
--> sql editor :
--> 데이터 조회되는 것 확인 가능
--> Batch 유형 선택 (전체 연동)
--> 시간 필드 선택 > timestamp

이렇게 설정해주기
- Set Properties : snort_input > 10초 > snortdb
- 참고 ) * * * * * : 분시일월요일 -> 일분 간격으로 실행하겠다

input name 설정
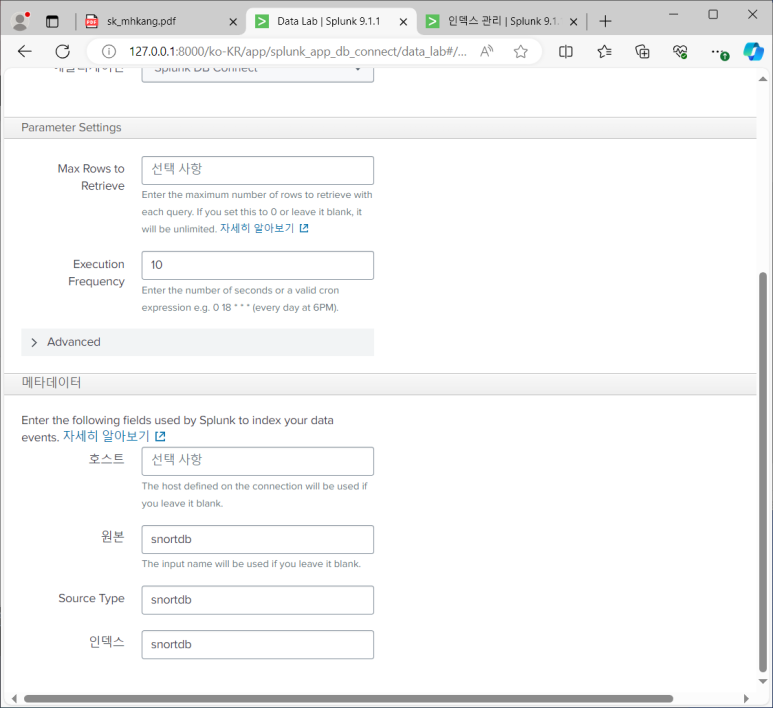
snortdb 설정

만들어진 것 확인
--> 재검색할때마다 늘어나는 데이터 확인 가능
- 안불러와지는 데이터 설정

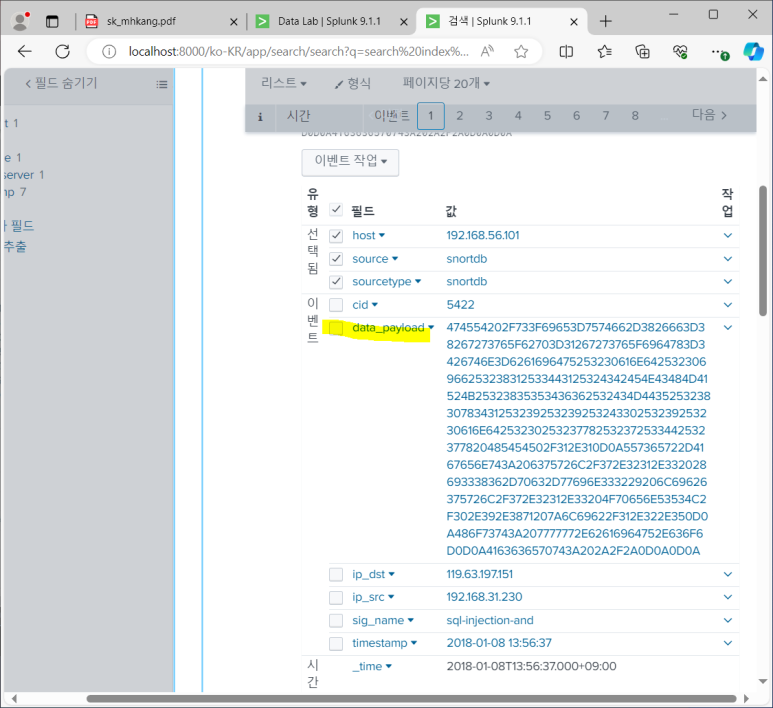
보인당
- Batch유형 대신 Rising 유형 사용해보기 (증분연동 : 추가된 값만 가져오는 것)
- 변경 기준 필드 : cid (발생 순서대로 매겨지는 번호), 최초 변경 기준 값 : 0
- 쿼리문 추가해주기
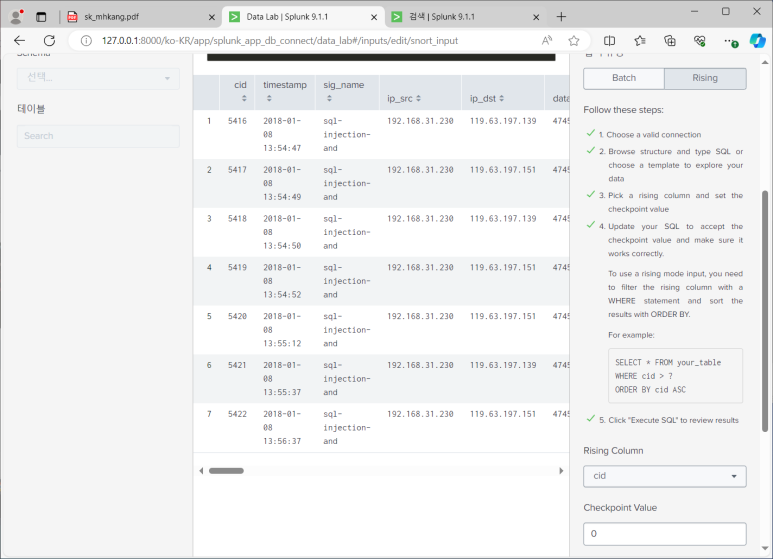
--> 수정된 쿼리문 executeSQL 실행 > 마치기 전에 앞서 만들었던 snortdb 인덱스 삭제하고 다시 새롭게 생성
--> 앱 > Search & Reporting > 전체 시간으로 변경 > index=snortdb 검색
--> 데이터가 잘 불러오는 것 확인
- 16진수 디코딩
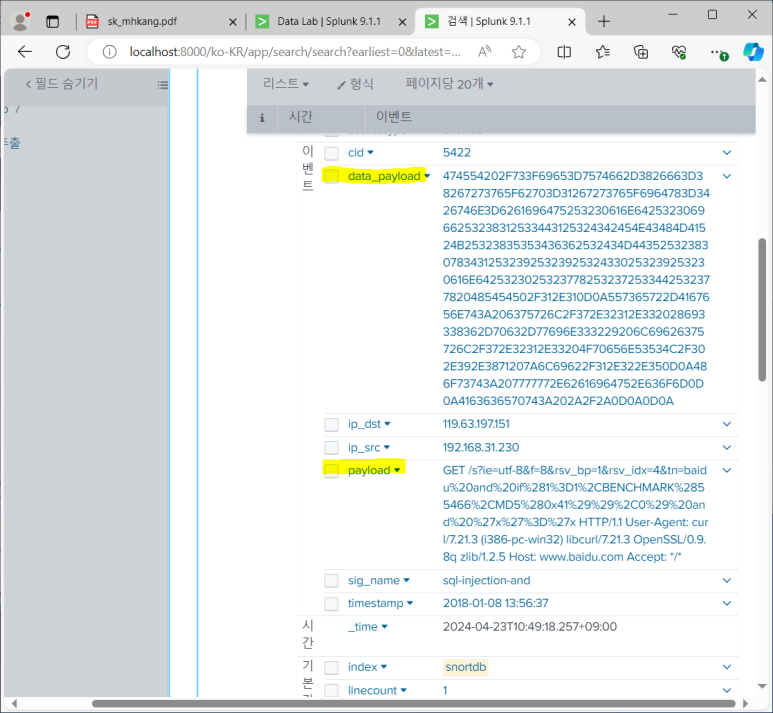
- 16진수 디코딩 (decrypt 앱 설치) : 디코딩 하고 싶은 필드 지정해서 해주는 앱
- decrypt2 설치 (파일에서 앱 설치)
- 계속해서 디코딩된 채로 보고 싶으면 계산된 필드 설정

- 룰 추가해서 잘 들어오는 지 확인해주기

rule 수정

연동되는 이 부분도 바꿔주기

잘 들어옴
보안관제 관점에서 분석하기
- apache.log 파일 올리기
- 어제 테스트했던 인덱스들 지우기
- apache 인덱스 새로 만들어서 파일 업로드
- 소스 타입 지정 시 access_combined가 어떤 것인지 확인하기
- 데이터 전처리 관련 설정 : props.conf 에서 확인가능
--> /access_combined 검색해서 확인해보기

--> REPORT-access라는 클래스에서 access-extractions라는 작업 정의중
- 실제 작업은 transforms.conf에서 세부 작업 진행함

- 만들어진 apache.log 검색 시작
- 보안 위협 요소를 알기 위해 데이터 요소를 알아야 하고 어떤 필드를 봐야할 지 파악 가능
- splunk가 필드 분류 잘 해 줌
--> 엑셀에서 확인했을 때 많이 쪼갤수록 잘 확인해 볼 수 있었는데 그걸 splunk가 잘 해 줌
- 제일 중요한 파일 정보만 따로 추출해줌 (url에서 가장 중요한 정보라고 볼 수 있는)
--> 이걸 분석하기 위해 의미를 잘 알고 있어야 하는 것
- referer 정보는 존재하는 경우가 있고 존재하지 않는 경우가 있음
--> 처음보는 데이터 파악 시 집계함수 사용하면 더 빠르게 파악해 볼 수 있음


--> 이렇게 처음 보는 것들이 무엇을 의미하는 지 아는 것이 중요
- web log는 무엇일까?
- 사용자가 요청했고 뭐라고 응답했고 언제 발생했고 사용자 IP는 뭐고 등이 있음
--> 여기서 가장 중요한 것이 어떤 요청을 했고 어떤 응답을 받았는 지인데 그 정보를 조합해 둔 것이 web log
- 보안 관점에서 분석해야할 것은 뭘까?
- 정상적인 사용자면 정상적인 요청을 했을 것이고 해커는 비정상적인 것을 요청했을 것
--> 보안 관점에서 가장 중요하게 봐야하는 것이 요청 데이터
- 그럼 이제 메소드 상태를 봅시다
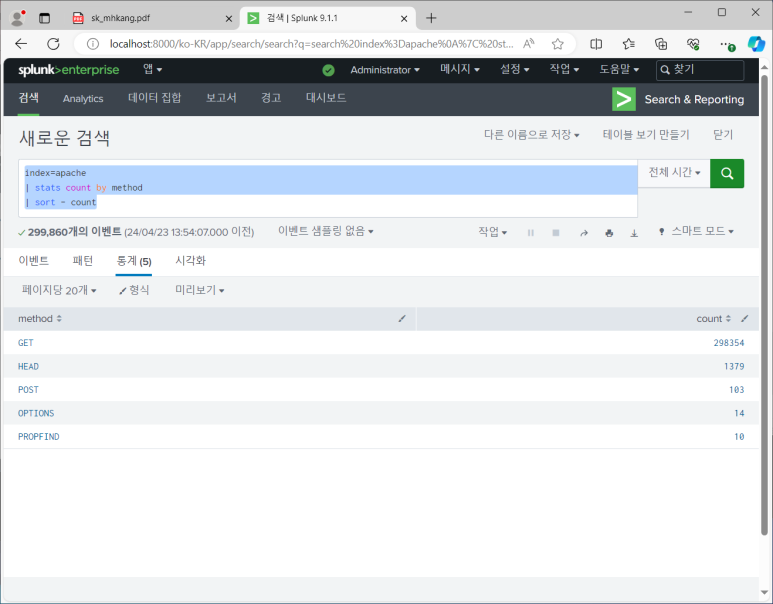
- 보통 보안 관점에서 GET과 POST 정도만 허용하는데 많지?
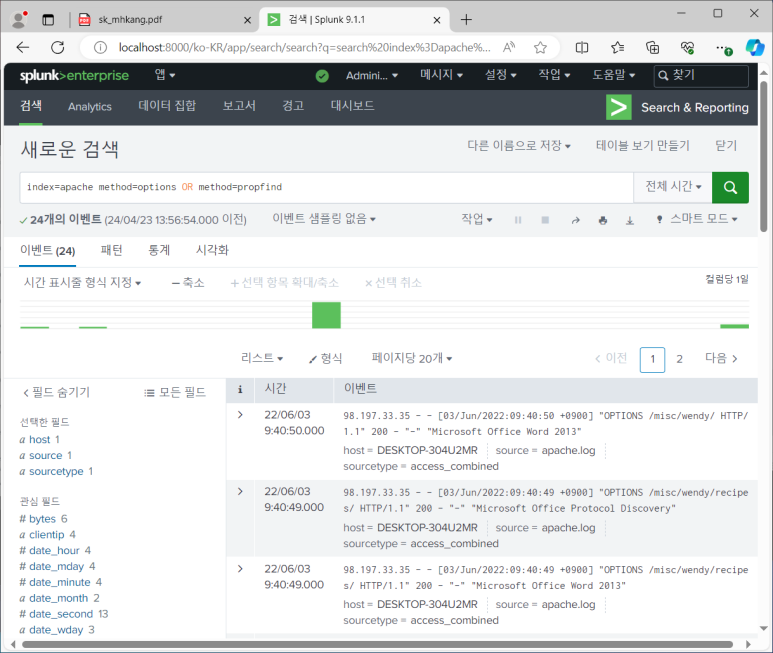
- 200은 정상처리, 500은 처리 못한 것
- PROFIND 최상위 경로로 접속 시도했으나 500 응답 확인 가능
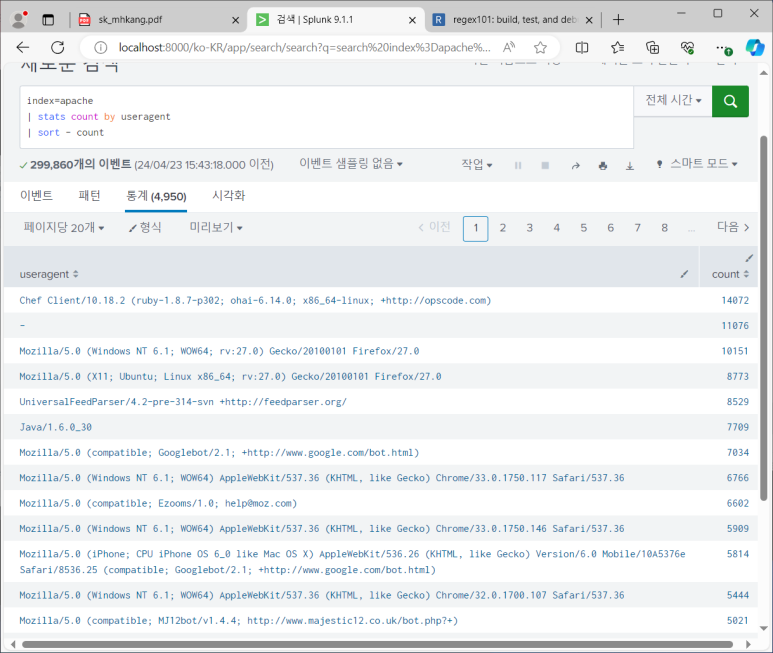
- 사용자 정보도 확인해 볼 필요 있음
- 사람만 인터넷 사용하는 것이 아니고 MS 같은 것들도 사용함
- 확인해보니 주목할 만한 사고는 없었음을 알 수 있다
--> 그럼 일상적이지 않은 method를 사용한 IP를 조사해보자
--> 이렇게 method도 해보고 이상한 IP 찾아서 검색하고를 한 번에 할 수 있음

- 이제 url 필드의 상태를 보겠음


- 튀는 로그가 보임
--> 날짜 확인해서 지정해보자

- 응답 코드별로 쪼개서도 봐보자

--> 404만 봐보자
--> 다른 날짜로도 검색해보기
- 이런식으로 숫자 변화만으로 이상징후 감지 가능
--> 이상 징후 잘 활용 시 패턴이 없어도 감지 가능할 수 있음
- 처음엔 요청 정보의 전체 정보를 보고 튀는 정보의 요청 응답 보기
- 이제 변수 필드 확인

- 5월 27일 날짜로 범위 줄여서 봐보기
--> 보니까 11시부터 15시까지 많았음
--> 이 시점의 원본 데이터 보기
--> 변수 내용 보며 파악 가능
- 기타 여러가지 확인해보기
- 가장 중요한 것이 file
--> 경로는 같지만 파일이 다르거나 경로는 다르지만 파일이 다른 것 배제하는 것
- 지표를 다양하게 추출하기
- 만약 url에 파일 정보 없고 경로로만 끝나면 default 파일로 연결되는 것
- 파일 정보 있는 것만 추출할 것
--> 확장자만 추출해보자


- 다양한 데이터 가공을 통해 다양한 데이터 지표 분석해보기
- 이제 404 상태의 변수 살펴보기


- 응답 상태 기준으로 확인해보면 400번대 에러들이 많이 발생한 것 보임
- 지표 다양하게 분석하면 이상징후 탐지 확률 높아진다고 백번 정도 말하심
- tool을 이용해서 공격하면 과거 uri 정보가 없기 때문에 useragent가 도움이 되는 정보가 될 수 있음
- 이게 없다는 것은 정상적이지 않은 방법으로 들어온 걸 수도 있기 때문
- 운영체제 정보와 웹 브라우저 정보, 디바이스 정보가 여러가지 형태로 묶여있음
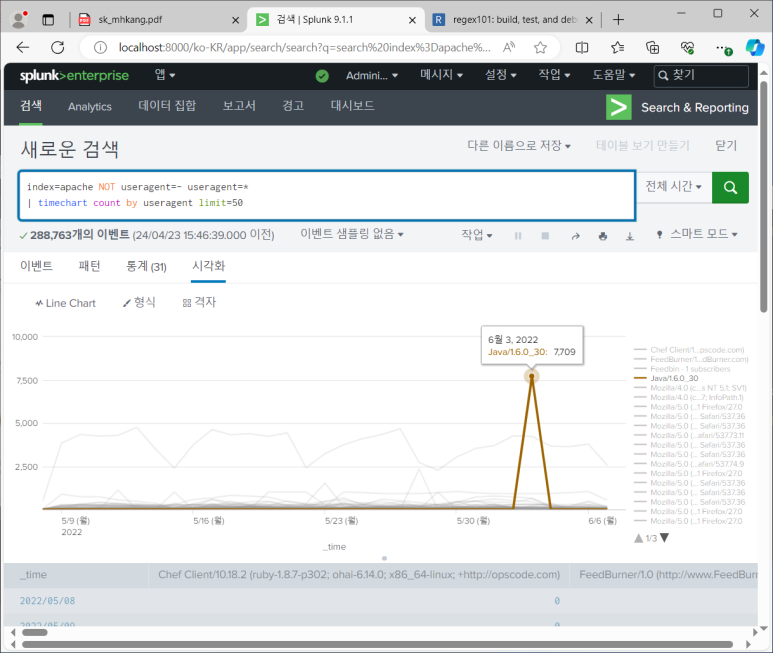
- JAVA 튀는 것 확인 가능
- URL이나 변수와는 달리 한번에 이상 징후 찾아내기 힘듦
--> 너무 다양하게 발생하고 있는 확인해야 할 변화들이 많기 때문
--> 패턴을 일반화 시켜보자!
- 앱 추가해서 분석해보기
- TA-user-agents : useragent 추가적으로 분석 보강해주는 앱
- 앱> 앱 업로드> 파일에서 앱 설치> 재시작
- 설정 > 룩업 > 룩업정의 > user_agents가 생성된 것 확인 가능
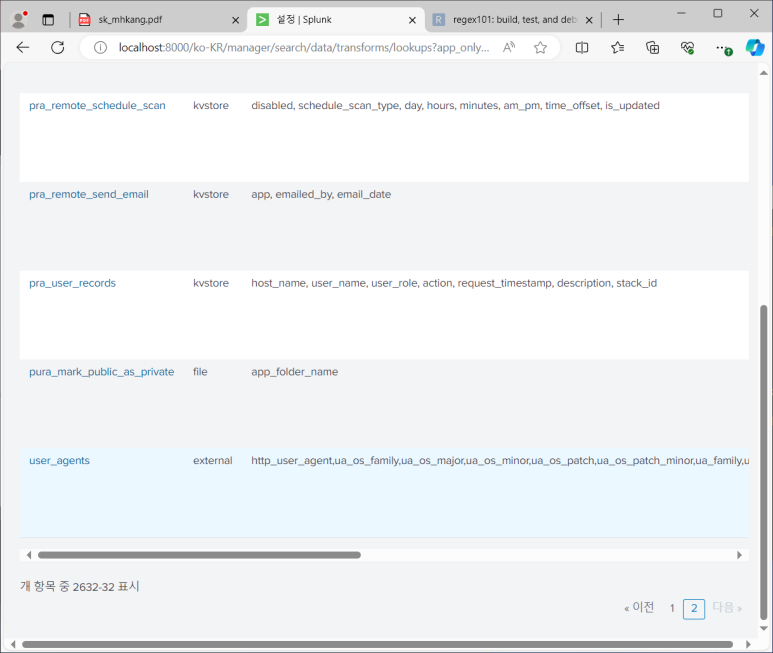
- 설정 > 필드 > 필드 별칭
--> 이전에 만들어 둔 access_combined 확인 가능
--> 여기에 추가해주기 useragent=http_user_agent
--> 확인!
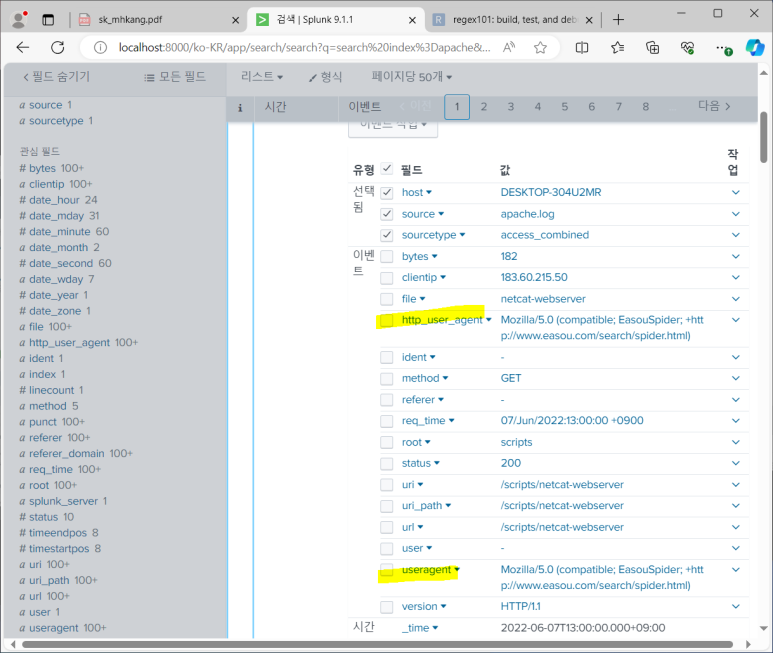
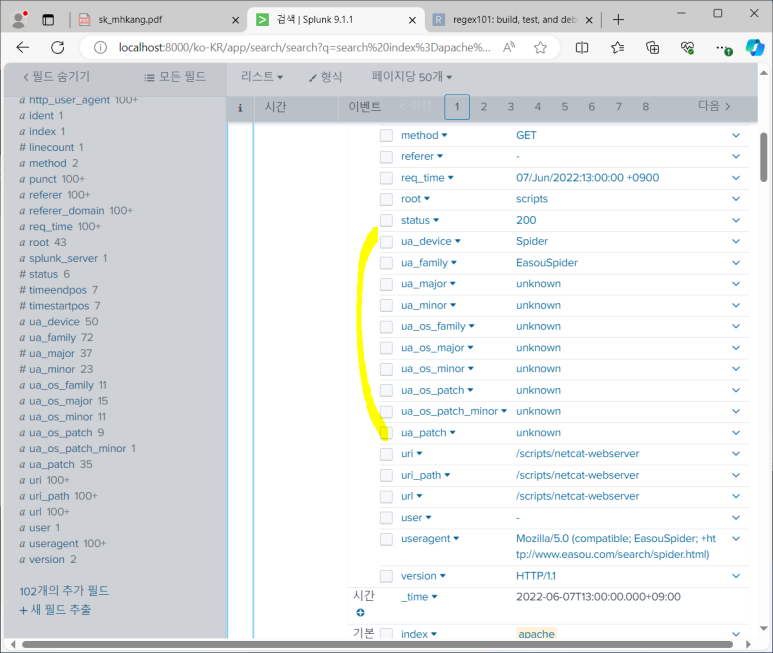
- 근데 속도가 좀 느림

- 그래서 느림
- 웹 브라우저 유형 좀 더 쉽게 파악 가능

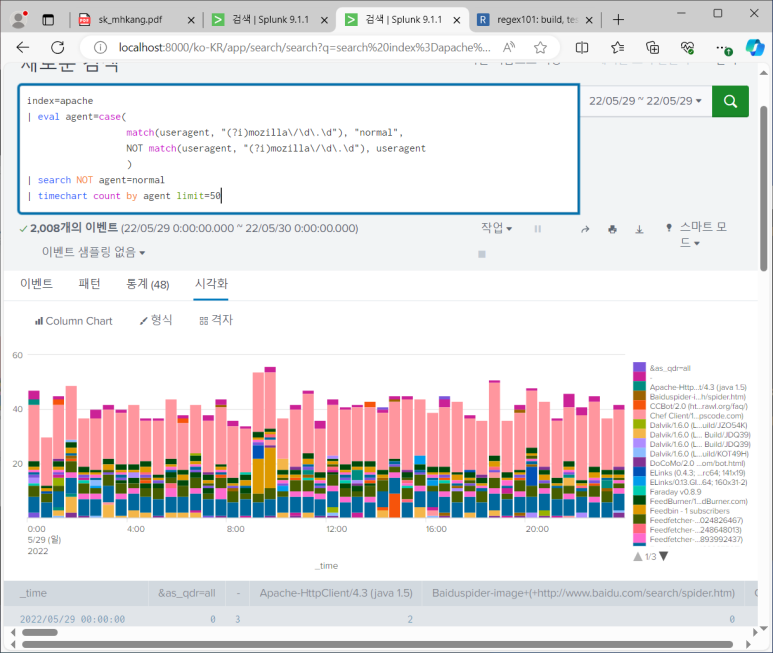
- 이제 히트맵 차트를 추가해보자
- 앱 > 앱 업로드 > 파일에서 앱 설치
--> 얘는 앱에 표시되지만 도움말 페이지로 이동하는 것
--> 히트맵 실제 적용해보기

확장자 필드 만들기
- 필드 > 계산된 필드 > 새로 추가
- 값 : access_combined
- 이름 : ext
- 평가식 : replace(file, ".*\.(.*)", "\1")
- ext = replace(file, ".*\.(.*)", "\1")
변수 길이 필드 만들기
- 값 : access_combined
- 이름 : param_len
- 평가식 : len(param)
- param_len = len(param)
IP 지리정보
- 정확한 위치를 알고 싶을 때는 위경도 좌표 찍으면 됨

iis.log 보기
- Vim으로 확인해보기
- 빈 칸으로 구분되어 있는 것을 확인 가능
- useragent 부분은 윈도우 웹로그가 빈칸을 +로 바꿔버림
- 필드 구분할 때 빈칸으로 구분하는데 useragent에 빈 칸 있으면 불편해서
--> apache는 큰 따옴표로 묶음
--> 이렇게 데이터를 저장해두는 게 다름
secure.log 보기
- 날짜 정보 > 컴퓨터 정보 > 프로세스 > 프로세스넘버 > 메시지
- 메시지 구간부터는 전체 데이터의 구조가 같지 않다

- 데이터 전처리
- 컴퓨터 정보 남기고 다 지우기
--> 임의의 문자 25개 검색: /\v^.{25}
--> 빈칸으로 치환: :%s///
--> 빈칸으로 시작하는 모든 문자 검색: / .*
--> 빈칸으로 치환: :%s///
--> 중복제거: : sort u
- 프로세스 정보 남기고 다 지우기

- 키워드 필드 추출 : 이거는 내 맘대로 해봤는데 돼서 기뻤음
- ip주소만 추출
- /\v\d+\.\d+\.\d+\.\d+
- 검색 결과 좌우에 구분기호 넣기
- ID 정보만 추출
- /\v (for invalid user|for user|for) (\S+)
- ID 없는 줄 지우기 server로 시작하니까 :%s/s.*///
- 그럼 이제 ID 값만 남음

splunk에서 secure.log 보기
- 파일 업로드하기

- 어떻게 처리되는 지 보기
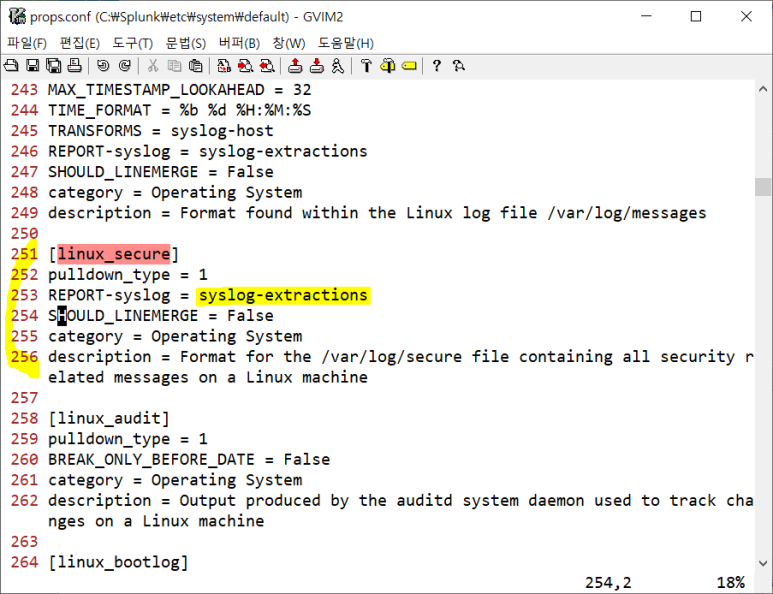
- 보니까 실제 작업은 suslog-extractions 로 됨
- transforms 가서 보기
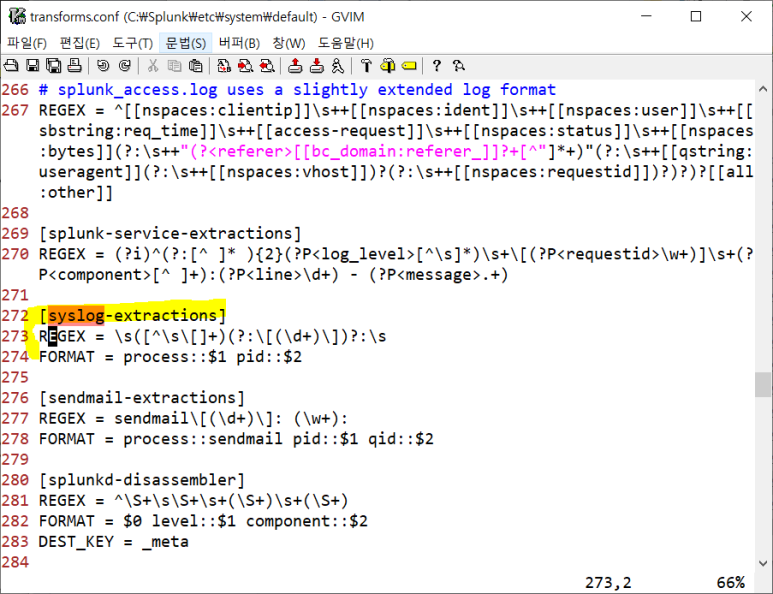
- process와 pid 추출 방식이 보임
- linux_secure 전처리 좀 더 추가해주는 앱 설치
- 기존에 만든 securelog 삭제
- 파일에서 끌어와서 앱 설치 (소스타입 강화된 것임)
- 설정 파일 확인해보니 다양한 필드 구분 지원중
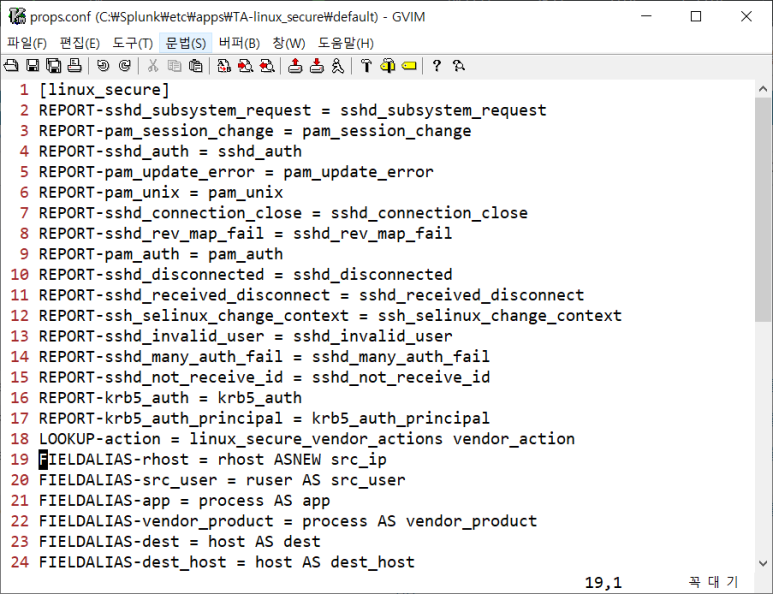
많은 클래스들과
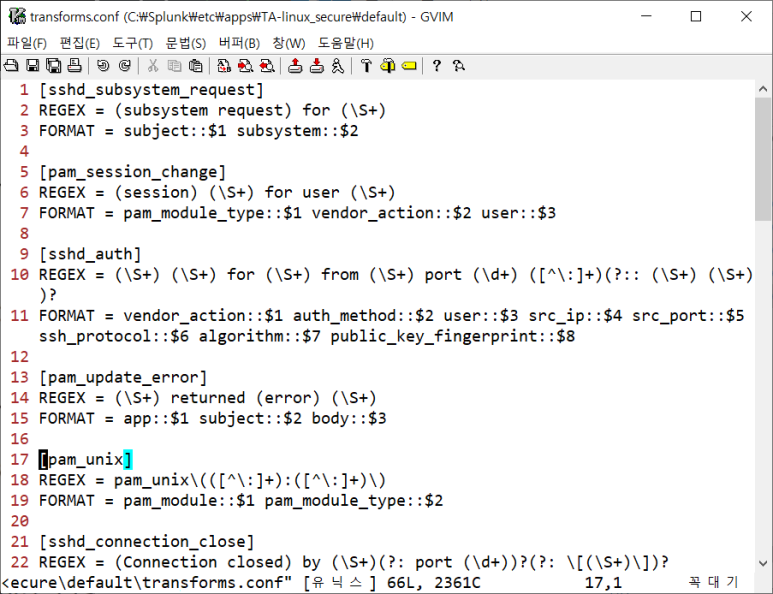
필드 분리
- securelog 새로 만들기
- 아까는 process와 pid만 추출됐지만 이제 많이 추출됨
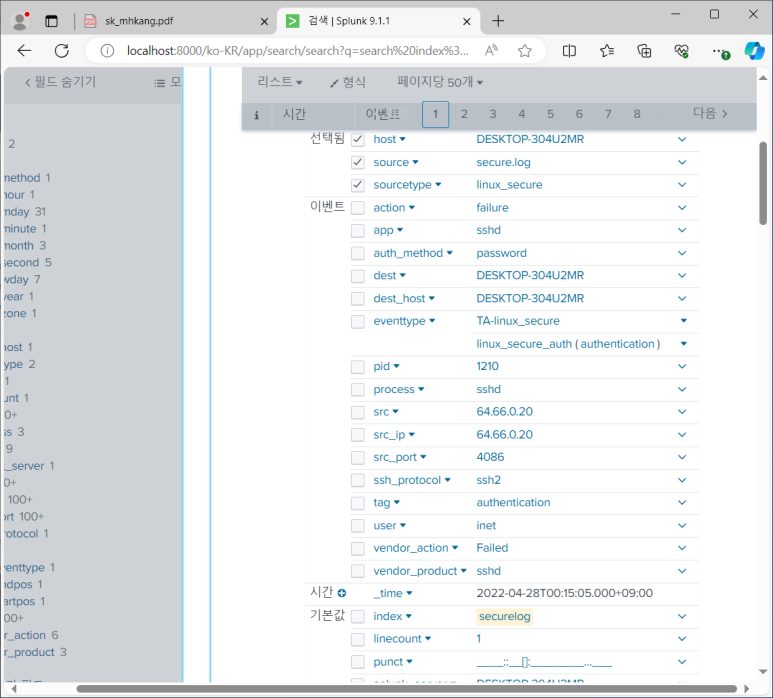

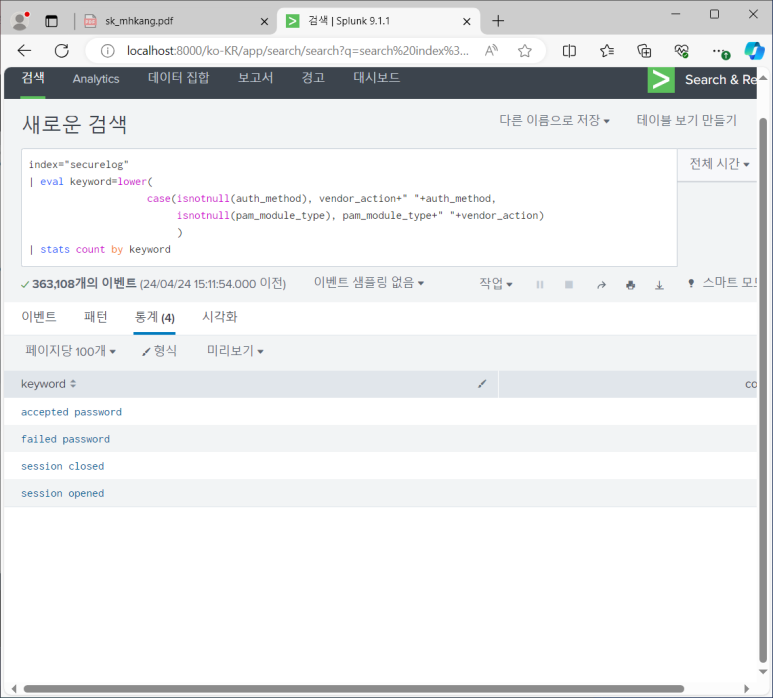

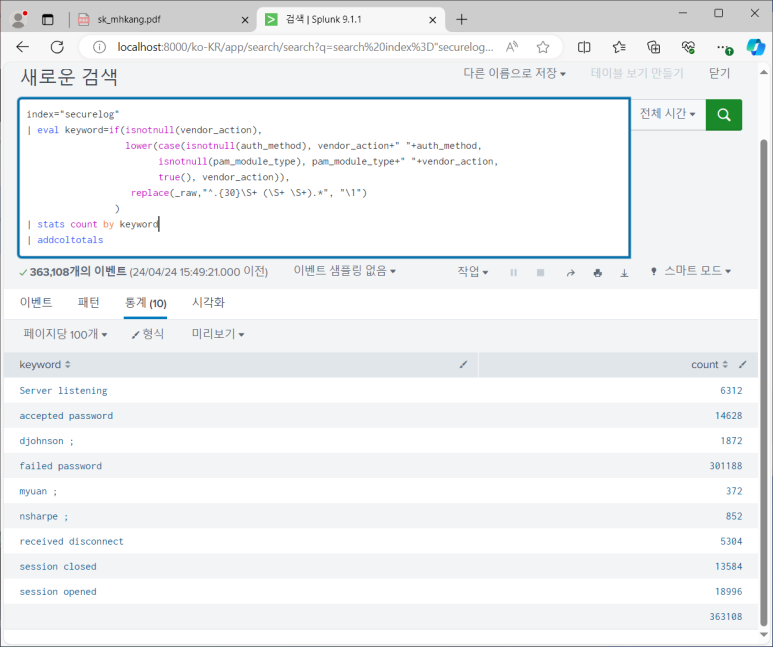
- keyword 필드 추가하기 > 계산된 필드
- 이제 그냥 keyword 바로 나옴
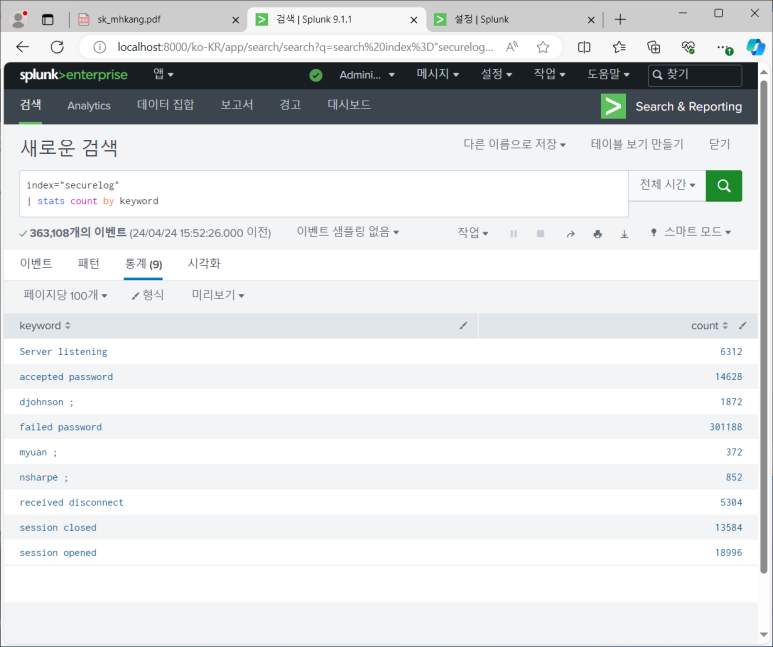
- user도 만들어주기
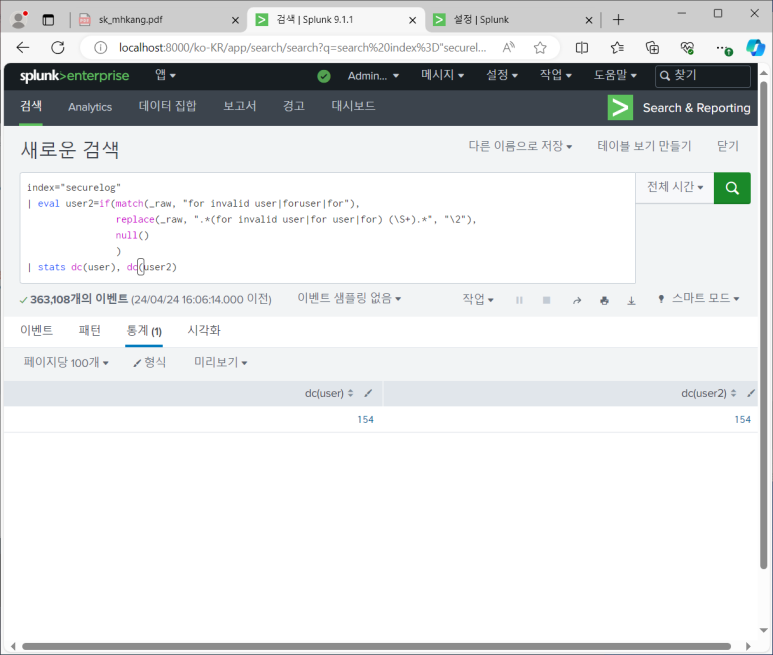
- 접속 성공 IP 찾기
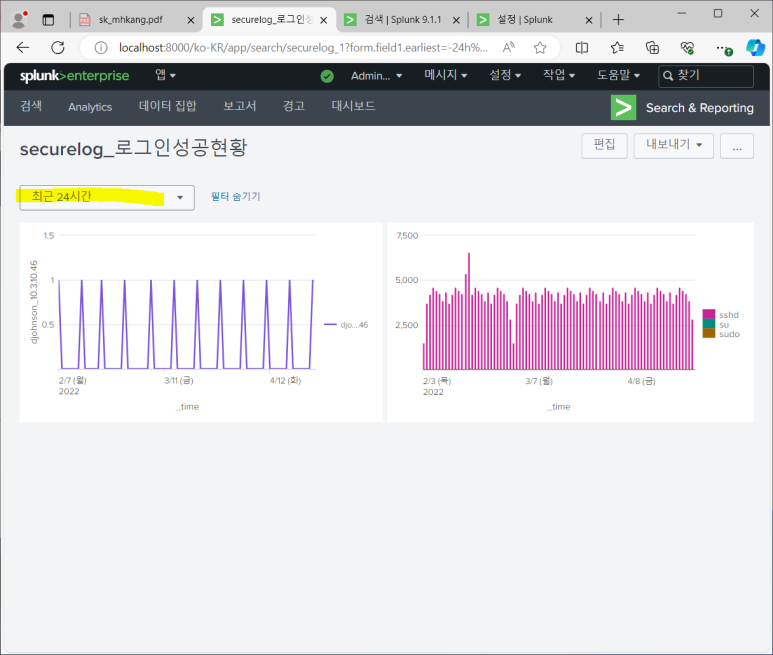
- 대시보드에 저장하기
- 다른이름으로 저장 > 새 대시보드
--> 대시보드에서 바로 볼 수 있음

- 편집 > 패널추가 : 새로운 차트 추가

- 편집 > 입력추가 : 추가적인 차트 컨트롤 기능 넣는 것
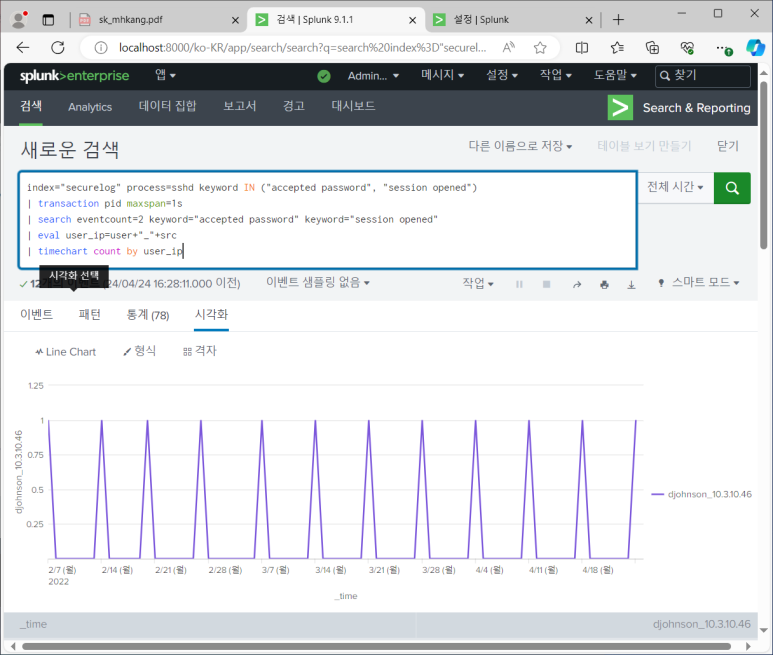
--> 근데 이게 시간추가하면 원본모드가서 수정해줘야 함
--> 원본모드 : xml 포맷으로 저장되어있는 것 볼 수 있음
--> 그래서 첨부터 대시보드에서 만들면 편함
- 대시보드 만들기
- 여기서 시간 추가하고 패널 추가에서 공유된 시간 선택기 선택
--> 이제 시간 적용 가능

- 패널 추가

Elastic
오픈소스 기반의 풀 텍스트 검색 엔진
- 순차적 데이터 처리 구조
- 유연하고 탄력적인 데이터 처리 지원
- 로그 수집 및 가공 (Logstash) > 데이터 저장 및 인덱싱 (Elasticsearch) > 데이터 시각화(Kibana)
--> 이렇게 세개 합쳐서 ELK 혹은 Elasic Stack이라고 부름
Logstash
- 순차적 데이터 파이프라인 제공
- input > filter > output
- Jordan Sissel
- 주요기능
- 다양한 데이터 입/출력 지원
- 다양한 데이터 가공(필터) 지원
Elasticsearch
- 검색 라이브러리 루신 기반의 검색 엔진
- 2010년 공개 (Shay Banon)
- 주요 기능
- 검색, 통계, 대시보드
Kibana
- 웹 기반 데이터 시각화 도구
- Rashid Khan
- 주요 기능
- 검색, 통계, 대시보드
분산데이터베이스
- 노드 : 엘라스틱서치 실행단위
- 인덱스 : 논리적 데이터 저장 단위
- 샤드 : 인덱스에 대한 논리적 디스크 파티셔닝
- 샤드 복제 및 분산을 통해 부하 분산 및 백업 제공
- 노드 추가 시 인덱스 복제
- 로드 밸런싱 구조 제공 및 자동 백업
데이터 관리 구조
- 엘라스틱서치 VS 관계형 데이터베이스

- 인덱스가 헷갈릴 수 있지만 테이블과 같다고 보면 됨
- 개념은 같지만 부르는 용어가 다른 경우 있음
- 엘라스틱서치 : json 구조로 저장 및 관리
- 키바나로 볼 땐 테이블로 보여줌
- 관계형 데이터베이스 : 테이블로 저장 및 관리
Elasticsearch - jvm.options
- 엘라스틱은 자바 기반 -> 엘라스틱이 자바를 포함하고 있음
- jvm.opsions는 자바와 관련한 설정
- Xms4g는 초기 메모리 > 2g로 수정

--> xms는 초기, xmx는 최대인데 늘어나도록 두면 성능저하 발생하므로 둘 값 동일하게 맞추기
- vim으로 편집하고 나면 un~ 파일과 ~파일 생김
- un~파일은 undo히스토리 있는 파일
- ~파일은 백업 파일
--> 사용하고 싶을 때 ~ 지워주면 됨
elasticsearch.yml
- yaml 포맷 사용하는 것
- Cluster 이름 설정, Node 이름 설정, Paths, Memory, Discovery등이 있음
- 설정 바꿀 필요 있을 때 여기서 하는 것
elasicsearch실행하기
- elastic > bin > elastic.bat이 실행파일
- 일단 bin 들어와서 cmd 창 열기
- localhost:9200
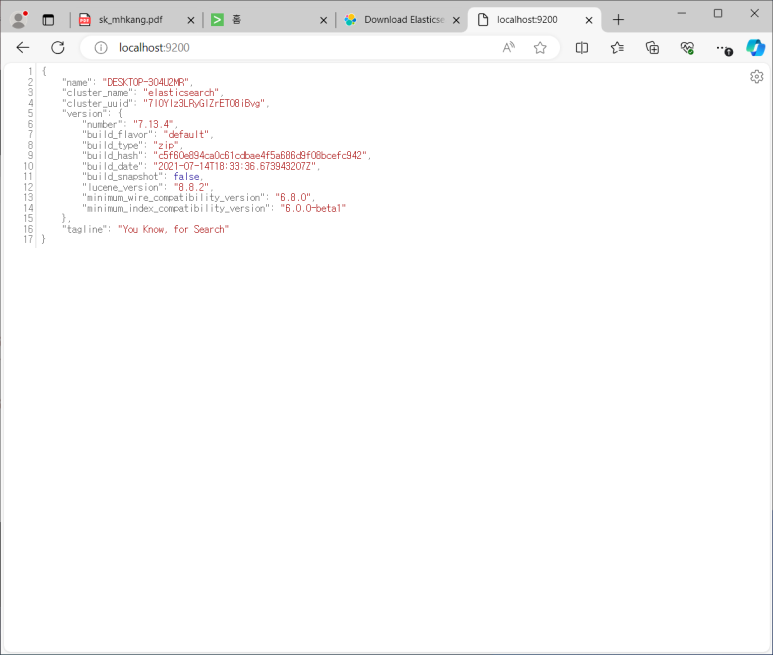
- 이게 나오면 이제 검색 엔진이 실행된 것
- 웹 요청 메소드로 데이터 불러오고 저장 가능
kibana.yml
- server.port : 키바나의 서비스 포트
- server.host : 키바나의 주소
- elasticsearch.hosts : 엘라스틱서치의 실행주소
- 키바나 혼자서는 암것도 못하는 겨
kibana 실행
- kibana > bin > cmd

- 사이드바 잠금 설정

- 이 기능 활용 위해 낮은 버전 사용하는 중
- 높은 버전이라고 데이터 분석 기능이 좋아지는 거라기보다 검색엔진 쪽이 더 좋은 성능 갖게 됨
IP 설정해주기
- splunk는 시스템에 할당된 모든 IP로 서비스를 제공해주지만 elastic은 localhost만 사용할 수 있게 되어있음
- 그래서 같은 팀원이 사용해야한다던가 하면 IP 설정 변경해줘야함
- elasticsearch.yml에서 network 설정
- 이렇게 IP 세팅을 하게 되면 클러스터 모드로 사용되는 것 (그전까지는 단독모드였음)
- Discovery 옵션은 노드 여러 대 사용 시 사용하는 옵션
- IP 세팅 했으니 클러스터 관리를 위해 관리 노드 필요
- elasticsearch network 바꿔줬으니까 kibana.yml도 바꿔주기
- 재접속

데이터관리 구조
- Management > Dev Tools
- 실행 키나 ctrl+enter 하면 명령어 실행됨
- 인덱스 생성 : testindex 만들어보기

- GET testindex 하면 testindex의 구조 볼 수 있음
--> settings : 물리적 구조 설정 (예시. shard 개수는 몇 개이고 등등)
- 실제 우리에게 가장 중요한 것은 mappings

- 데이터 입력

Logstash를 이요한 데이터 연동
- logstash.yml은 로그 스태시 프로세스 환경 설정
- 얘도 jvm 파일 있는데 보니까 xms1g로 되어있어서 그냥 둠!
- piplines.yml은 데이터 파이프라인 환경설정

- test.conf 만들기
- Input / Filter / Output 플러그인 구문
|
플러그인 {
① 옵션 => “단일 값”
② 옵션 => [ “첫째 값”, “둘째 값” ]
③ 옵션 => { “작업 대상(또는 source)” => “실행 작업(또는 target)” }
|
- elk > test.conf 만들기
--> 일단 실행

--> @timestamp는 불러온 시간
--> host는 데이터 가져온 컴퓨터 이름
--> path는 데이터 경로
--> @versiion은 데이터의 버전
--> 제일 중요한 데이터는 message에 한 줄로 데이터가 넘어오고 있음
----> 그러면 이제 필드별로 계산하기 힘드니까 나눠주자
- Filter 지정
- combined log = common log + referrer + agent

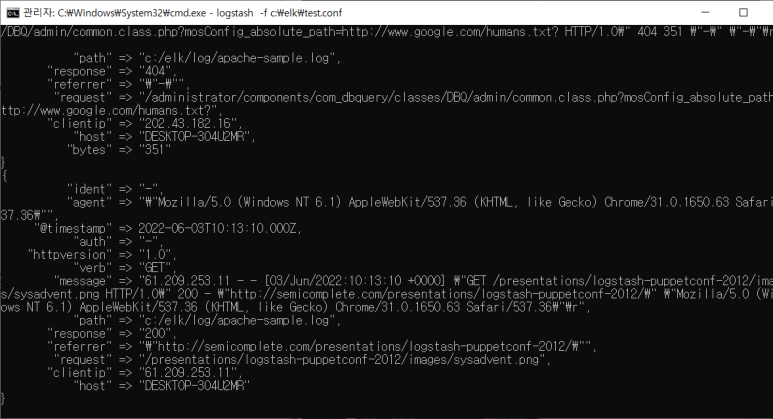
- 저장하기
- Kibana로 보기
- Stack Management > Data > Index Management
--> Indices는 인덱스 관리 페이지, Index Templates는 기본 골격
- 저장하고 보니 Indices에 하나 생김
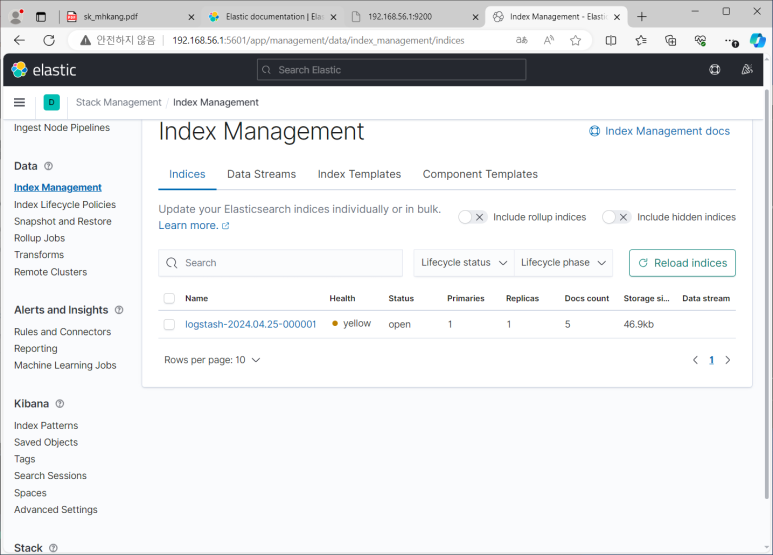

- 시간 정보가 다 2022로 되어있어서 apache-2022로 저장된 것 보임
- 이제 다 맘에 드니까 원본 데이터로 바꿔주기 (지금은 sample data 였음)
- 그래서 apache 로그로 바꿔주고 stdou{} 주서처리
--> stdout{}은 화면에 보여주는 명령어였기 때문에

- 엘라스틱에 저장되어 있는 것을 키바나로 보고 있는 것
키바나에게 필요한 것
- 엘라스틱 연결을 위해 엘라스틱 위치 : kibana.yml > elasticsearch.hosts옵션
- 데이터 조회를 위해 인덱스 이름 : Stack Management > Index Patterns (키바나 사이드바 메뉴)
- create index pattern > apache-2022 이름 설정 > @timestamp설정 > create
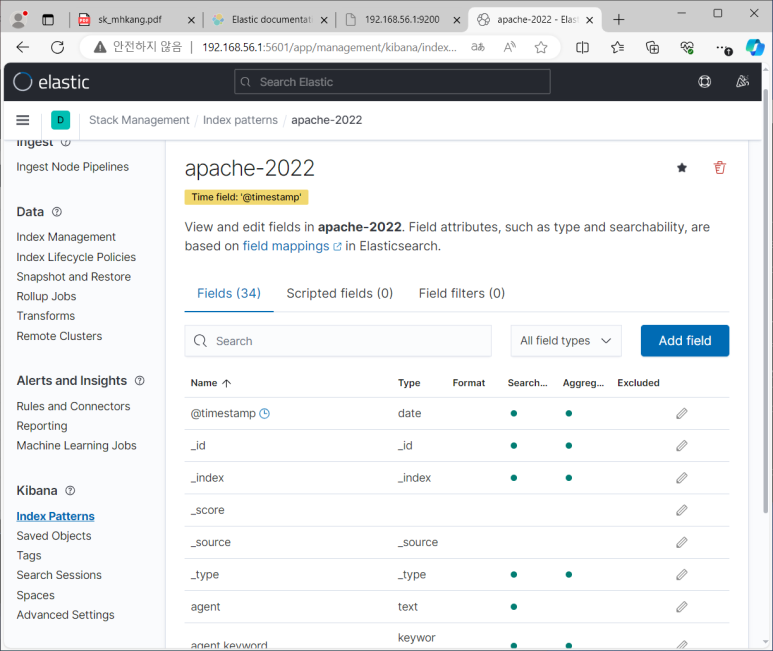
--> 같은데 다른 타입으로 저장되어 있는 항목들이 있음
--> 예시 ) text는 인덱싱 되어 검색 가능, keyword는 풀텍스트 검색은 안됨
- searchable : 검색가능한 것, aggregatable은 집계가능한 것
--> why? > 집계 작업을 위해! 풀텍스트로된 것들은 성능저하를 발생시키기 때문
--> 그래서 텍스트 데이터들이 필드 두개 씩 있는 것
검색하기
- Analytics > Discover

- 스플렁크처럼 검색해서 볼 수 있음
- Kibana에서도 Uploadfile 가능
- 제약사항 : 필드 구분이 되어 있는 파일들, CSV, TSV 등과 100MB까지만 연동 가능
- Apache-sample.log 올려보기
- override settings > 1000개의 데이터만 보여주는 중, Grok Pattern 보여주는 중

- import > simple | advanced > apache-sample > import
--> advanced에서는 내부적으로 어떻게 구성되는 지 보여줌
- index patterns 가서 확인
--> 여기서 보니까 타입 하나씩만 있음
- Discover > apache-sample해서 데이터 살펴보기
- 하나 더 올려보기
- iis-sample2.log는 안올라옴
- secure-sample2.log는 필드 분류 잘 안됨
- 아파치와 CSV 형식이 아니면 좀 별로임
--> secure-sample2.log 엑셀로 만들었던 것 CSV로 바꿔서 올려봤더니 잘 됨
Visualize Library
- aggregation based > vertical bar
- metrics : 계산 유형, buckets : 계산조건

- split series 해보기 > Terms가 필드를 의미함

- split charts 해보기

Lens
- Horizontal axis : X축
- Vertical axis : Y축
- Break down by : 시계열 분할 조건 필드
- 얘는 데이터 끌어오면 최적화된 차트 자동으로 보여줌
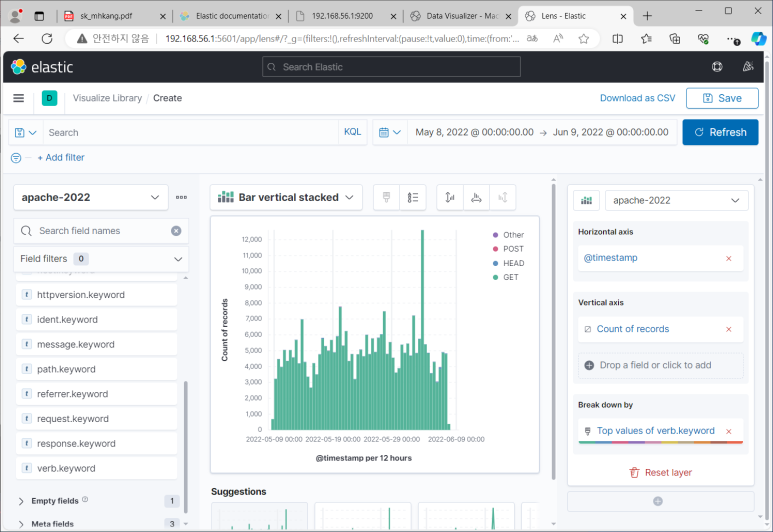
- 차트 저장해서 대시보드에서 볼 수 있음
Maps
- geoip 추가하기
- geo로 시작하는 필드들 확인 가능 및 위도 경도 필드 확인 가능
- maps 가보기
- add layer > documents : 위경도 좌표에 발생량 찍어주는 애
--> tooltip > geo.city, geocountry

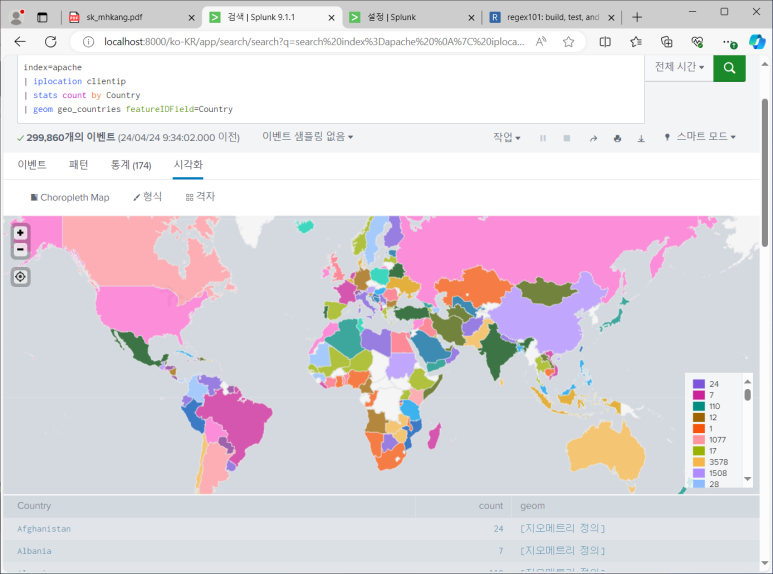
- add layer > choropleth
- world countries 선택하고 joinfield는 countrycode
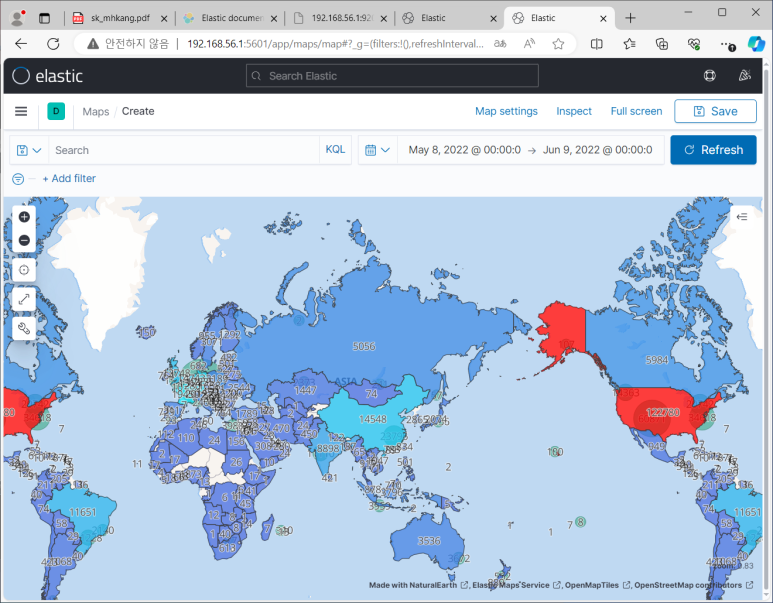
- 두 개의 레이어 순서도 바꿀 수 있음
- 얘도 저장 가능함 => 대시보드 추가해보기
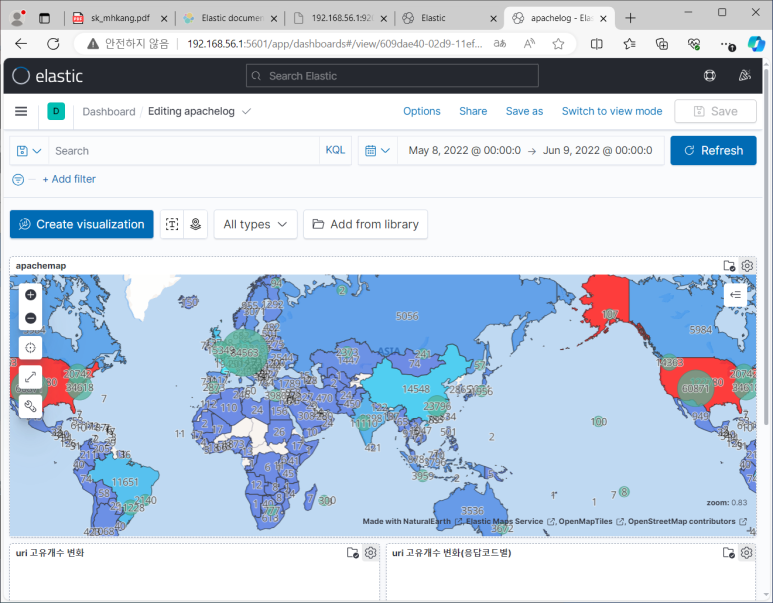
- 지도 그릴 때 인데스 이름 바꾸는 이유
- index pattern이 logstash-*이어야 탬플릿이 적용되고 geopointtype으로 만들어짐
DB 데이터 연결 준비
- Snort, SQLyog 실행
- jdbc라는 플러그인 사용할 예정임
- test.conf 수정
- 에러 남 보니까 연결에서 에러가 났다고 해서 snort 뒤에 ?useSSL=false 추가
--> SSL 보안 통신 안하겠다는 의미
DB 정보 받아보기
- barnyard, snort 실행 (eth0)
- wget 해보기
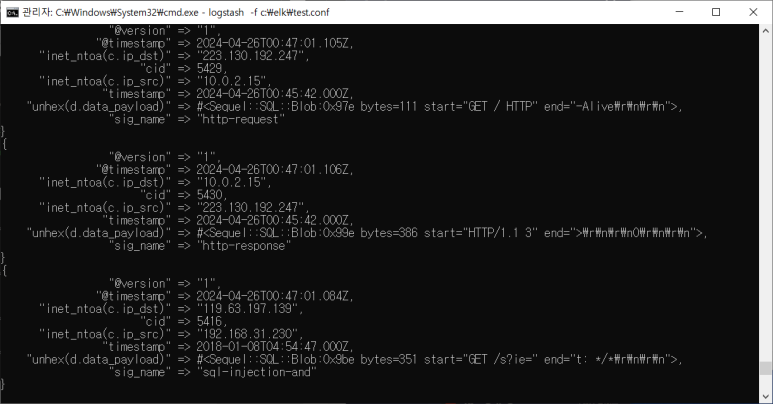
- DB에서 넘어온 정보여서 이미 필드 분류가 다 되어 있음
- 이제 이 상태로 엘라스틱에 저장하면 되겠죵?
- index management가서 reload해보면 snort-2024로 인덱스 새로 만들어진 것 확인 가능
- Kibana에서 index pattern 설정하기
- 여기서 시간필드는 원래 탐지로그가 저장되어있는 timestamp로 지정
- @timestamp는 불러온 시간을 의미함
- Discover에서 확인 가능
DB 지리정보 확인하기
- Index management > template
- logstash 가서 보면 geoip안에 있는 정보들이 보임
--> 출발지용과 목적지용으로 나눠져 있지 않기 때문에 새로 만들어줘야한다고 판단함
- snort 탬플릿 만들기 > index paterns : snort-*
- 나머지 다 default 값이고 mappings로 건너뛰기
--> mappings > geo_src : object -> location : geo_point (목적지도 동일하게 설정해주기)
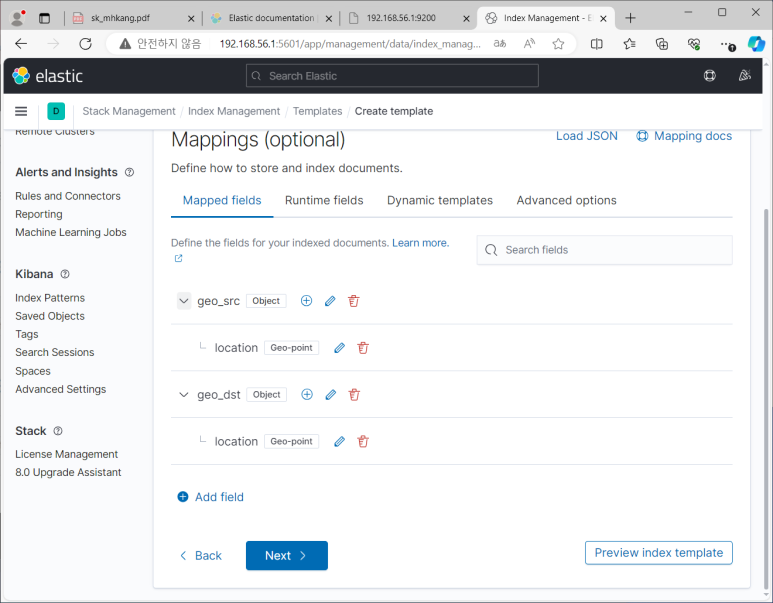
- index management가서 reload해보면 snort-2024로 인덱스 새로 만들어진 것 볼 수 있음
- test.conf 파일에서 필터 지정
- map 가서 document로 src와 dst 만들어서 어제처럼 확인해보면 잘 만들어지는 것 확인 가능
IP로그 연동
- 새 로그 파일 만들기 (test.log)
- 내용 ) a-b:c
- iptest.conf 파일 만들기

- 잘 되니까 ip.log로 바꿔서 확인해보기
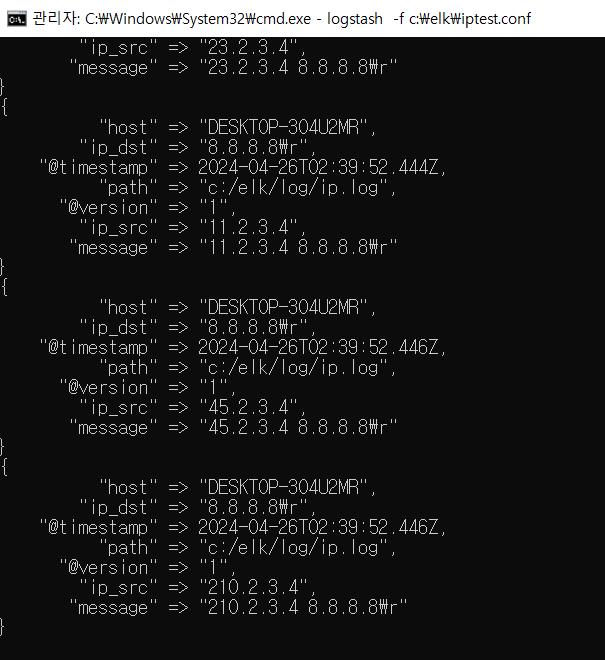
- \r이 문자로 인식되기 때문에 없애줘야 함

- 이제 지리정보 매핑 후 저장하기
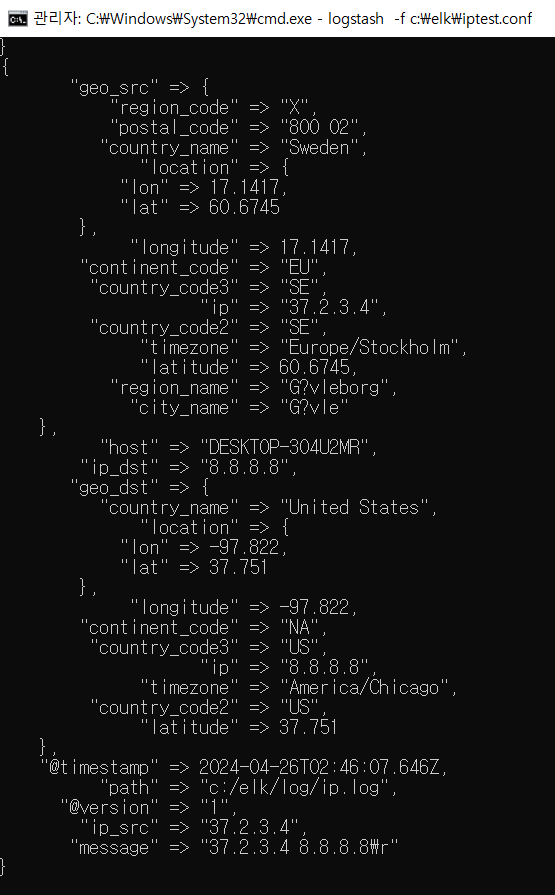
- Kibana에서 확인해보자
- 패턴 등록하기
--> geo_point 타입 잘 있나 확인해보기
- map 만들기
- src-dst 연결지도도 기존 것에 추가해서 만들어보기

apache 로그 분석하기
- 테스트 먼저 하면서 필요없는 필드 지우고 필드 분류해주기
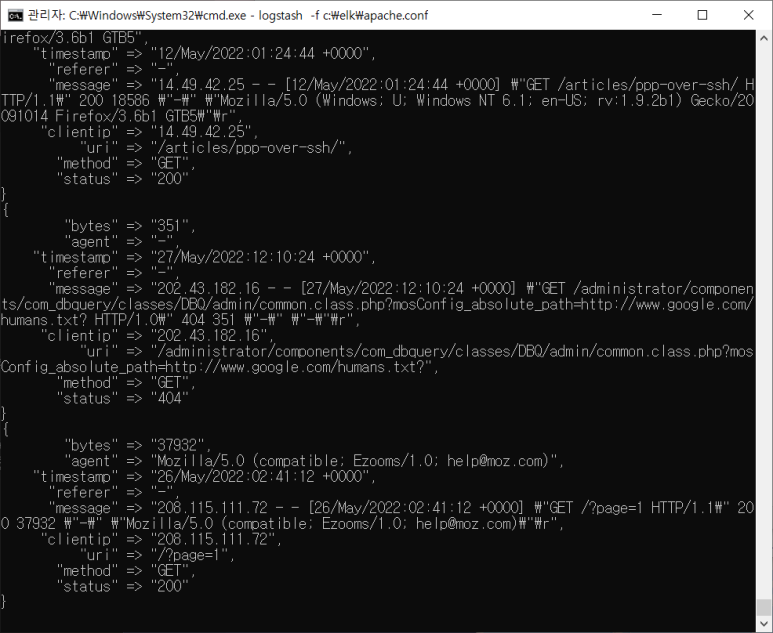
- uri 보면 url + 변수인데 변수가 있는 애가 있고 없는 애가 있어서 dissect 필터 이용해 ?로 구분 안됨
--> 조건을 주어야 함

- url에서 파일 정보만 추출해보려고 함
- 근데 파일 들어있는 위치가 다 달라서 이건 정규표현식 써야 함

- 확장자만 추출해보기
- 근데 .을 여러 개 사용하고 있는 파일이 있음 그래서 다르게 써 보자
- 변수 길이 추출하기
- splunk처럼 자동은 아니지만 원하는 필드 추출은 할 수 있음
- 원본 데이터로 바꾸고 저장하기
- 근데 시간으로 인식시키는 작업을 까먹고 안해줘서 해줍시다
- apache-2022 인덱스 확인 가능
- 인덱스 패턴도 만들어주기
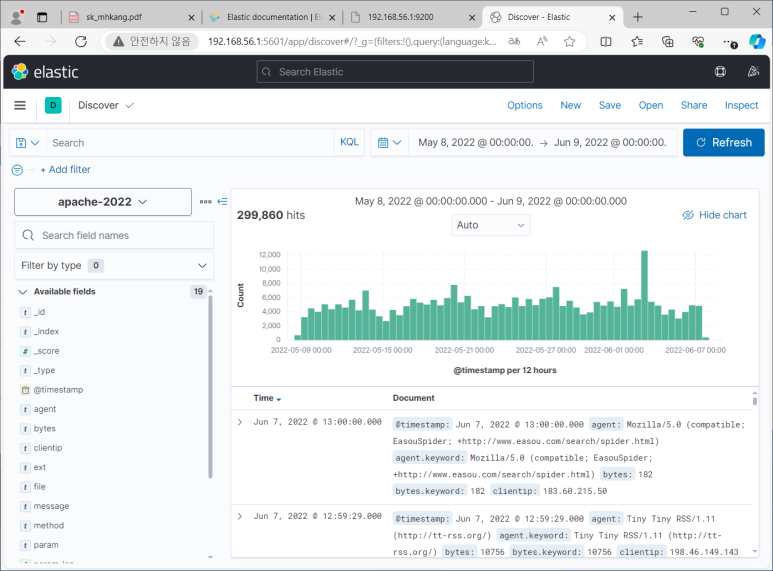
- 잘 들어왔쥬?
- 이제 Visualize로 가서 Lens로 데이터 차트도 한 번 그려보고 하는 추가 분석 작업 해주면 되겠죠?
iis.log 살펴보기
- 마찬가지로 sample log로 먼저 해보기
- warning : character encoding > 요 것은 한글 때문에 난 에러
--> 보내주는 데이터의 한글이 있음을 알려주는 옵션 추가
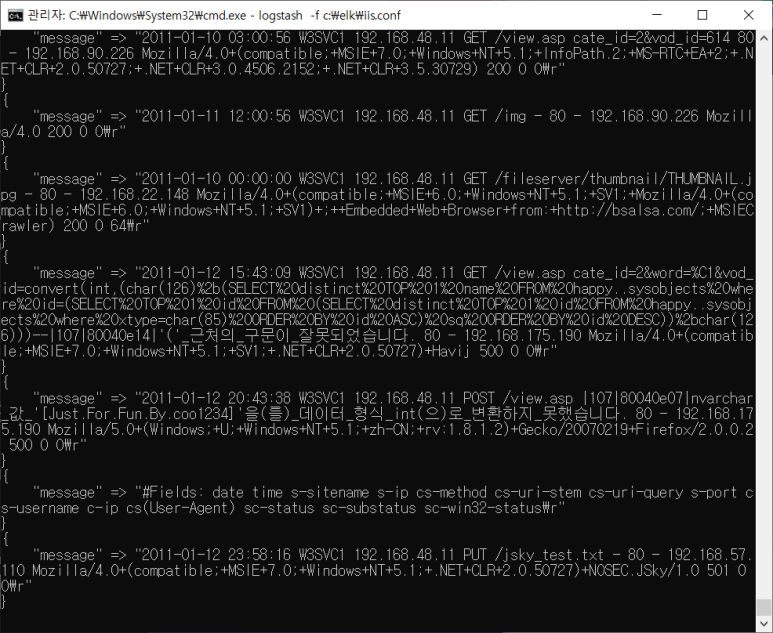
한글 보이지?
- 로그 첫 줄에 해당 로그의 필드 구조 설명이 있음
- 지워주자 (주석 기호 붙어있는 것 활용하기)
- 문제는 #이 어디에 있어도 다 지워져버리는 것
--> 위치가 처음인 경우에만 지워져야하니까 정규 표현식 이용하자
- 날짜, 시간 정보 추출하기
- 나머지 필드 분류
- 시간필드 작업
- useragent 나누기
- 값이 존재할 수도 있고 안할 수도 있기 때문에 잘 구분해 줘야 한답니다
- 근데 해봤더니 별로야 왜냐면 agent 안에서 빈칸대신 +를 사용하고 있어서 불완전한 정보임
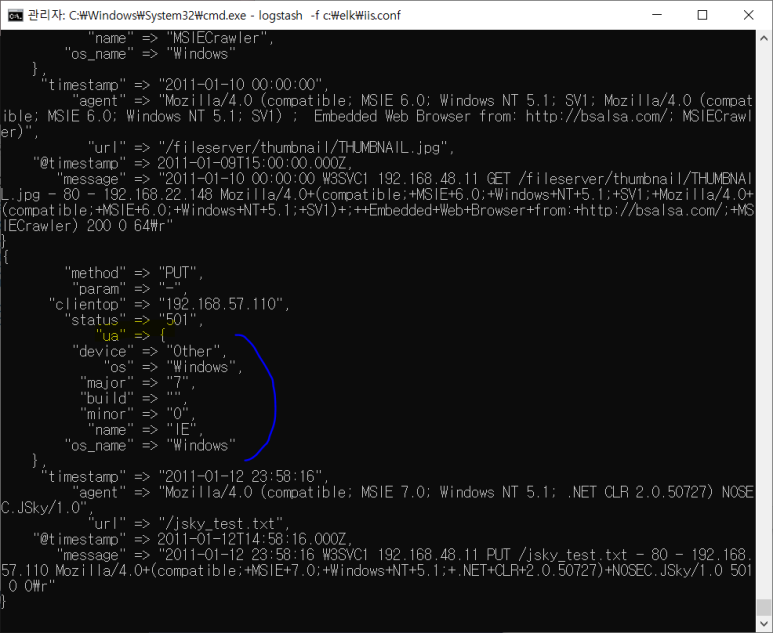
*필드 순서 바뀌어서 나오는 게 불편하다면
- 자 이제 설정 다 했으면 실제 로그로 바꾸고 엘라스틱으로 보내주고 또 분석해보고~~
secure.log 살펴보기
- 얘도 테스트부터겠지~
- conf 파일만들고 cmd에서 시작
- 필요없는 거 지우고 timestamp 만들기
- 필드 나누기
- 키워드 뽑아보기
- 정보들 추출해보기
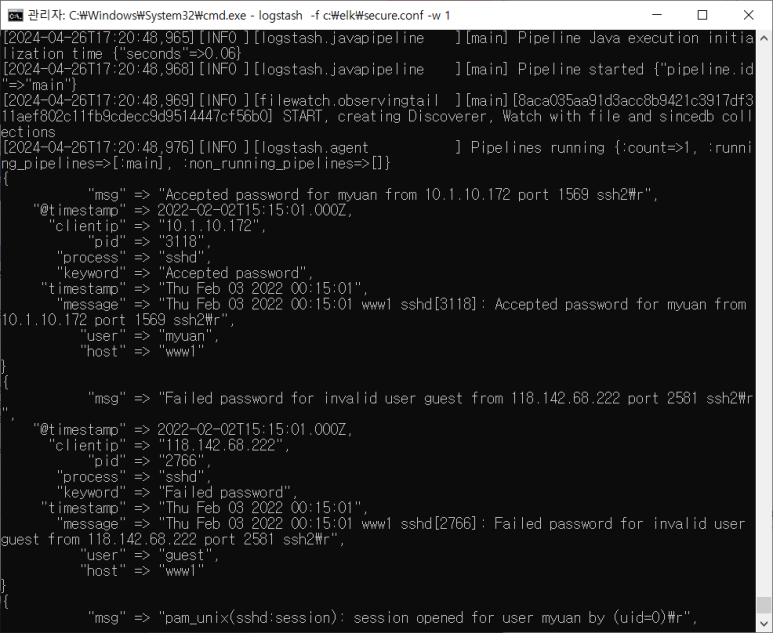
- 이제 완벽하다 싶으면 똑같이 원본 넣고 엘라스틱 보내고 분석~~